





count(1)、count(*)、count(列名)的区别
在平时开发,或者写sql过程中,没怎么注意过count(1)、count(*)、count(列名)的区别,本文,将结束一下这三者的区别。
1. count(1) and count(*)
从执行效果来看,count(1)和count(*)的效果是一样的。
当表的数据量大些时,对表作分析之后,使用count(1)还要比使用count()用时多! 当数据量在1W以内时,count(1)会比count()的用时少些,不过也差不了多少。
如果count(1)是聚集索引时,那肯定是count(1)快,但是差的很小。 因为count(),会自动优化指定到那一个字段。所以没必要去count(1),使用count(),sql会帮你完成优化的, 因此:在有聚集索引时count(1)和count(*)基本没有差别!
以下来自官方文档:
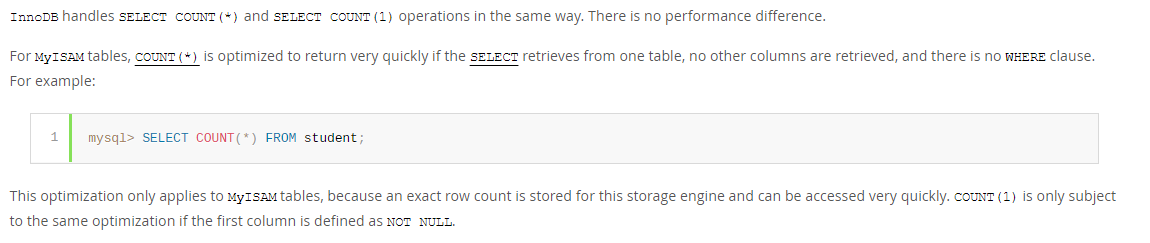
*InnoDB处理count()和count(1)采用的是一样的方式,没有性能上的差别。**
2. count(1) and count(字段)
两者的主要区别是
- count(1) 会统计表中的所有的记录数,包含字段为null 的记录。
- count(字段) 会统计该字段在表中出现的次数,忽略字段为null 的情况。
即不统计字段为null 的记录。
3. count(*) 和 count(1)和count(列名)区别
执行效果上:
- count(*)包括了所有的列,相当于行数,在统计结果的时候,不会忽略为NULL的值。
- count(1)包括了忽略所有列,用1代表代码行,在统计结果的时候,不会忽略为NULL的值。
- count(列名)只包括列名那一列,在统计结果的时候,会忽略列值为空(这里的空不是指空字符串或者0,而是表示null)的计数,即某个字段值为NULL时,不统计。
执行效率上:
- 列名为主键,count(列名)会比count(1)快
- 列名不为主键,count(1)会比count(列名)快
- 如果表多个列并且没有主键,则 count(1 的执行效率优于 count(*)
- 如果有主键,则 select count(主键)的执行效率是最优的
- 如果表只有一个字段,则 select count(*)最优。
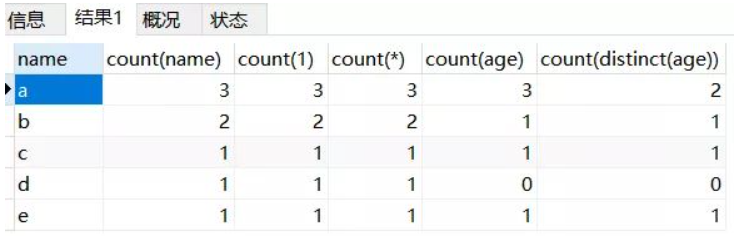
4. 实例分析
1 | create table counttest |
5. 一些问题
在INNODB与MYISAM中统计当前数据行,用count(*)有什么区别?
MyISAM对于表的行数做了优化,具体做法是有一个变量存储了表的行数,如果查询条件没有WHERE条件则是查询表中一共有多少条数据,MyISAM可以做到迅速返回,前提条件是没有where语句的哦, InnoDB不保存表的具体行数,执行select count(*) from table时需要全表扫描。
那么为什么InnoDB没有了这个变量呢?
因为InnoDB的事务特性,在同一时刻表中的行数对于不同的事务而言是不一样的,因此count统计会计算对于当前事务而言可以统计到的行数,而不是将总行数储存起来方便快速查询。
InnoDB会尝试遍历一个尽可能小的索引除非优化器提示使用别的索引。如果二级索引不存在,InnoDB还会尝试去遍历其他聚簇索引。 如果索引并没有完全处于InnoDB维护的缓冲区(Buffer Pool)中,count操作会比较费时。
MySQL查询一定大范围的数据和在Redis中查询一定大范围的数据量,那个更快一点?
Redis的查询效率比Mysql查询效率要快;因为Redis的数据是保存在内存中, 我们可以直接去内存中读取数据,这样的效率更快一点,而MySql数据是保存在磁盘中,每次查询数据我们都要去磁盘进行IO读取,大大增加了查询时间,同时还会涉及到回表的问题,影响查询效率。
Redis存储的是k-v格式的数据。时间复杂度是O(1),常数阶,而MySQL引擎的底层实现是B+Tree,时间复杂度是O(logn)**,对数阶。Redis会比MySQL快一点点。
Redis是单线程的多路复用IO**,单线程避免了线程切换的开销,而多路复用IO避免了IO等待的开销,在多核处理器下提高处理器的使用效率可以对数据进行分区,然后每个处理器处理不同的数据。
6. 总结
- 如果在开发中确实需要用到count()聚合,那么优先考虑count(),因为mysql数据库本身对于count()做了特别的优化处理。
- 有主键或联合主键的情况下,count(*)略比count(1)快一些。
- 没有主键的情况下count(1)比count(*)快一些。
- 如果表只有一个字段,则count(*)是最快的。
- 使用count()聚合函数后,最好不要跟where age = 1;这样的条件,会导致不走索引,降低查询效率。除非该字段已经建立了索引。使用count()聚合函数后,若有where条件,且where条件的字段未建立索引,则查询不会走索引,直接扫描了全表。
- count(字段),非主键字段,这样的使用方式最好不要出现。因为它不会走索引.