





Spring Cloud 和 Dubbo 有哪些区别?
SpringCloud和Dubbo都是当下流行的RPC框架,各自都集成了服务发现和治理组件。SpringCloud用Eureka,Dubbo用Zookeeper,这篇博客就将将这两个组件在各自系统中的作用机制的区别。
从Nginx说起
我们先从 Nginx 说起,了解为什么需要微服务。最初的服务化解决方案是给相同服务提供一个统一的域名,然后服务调用者向这个域发送 HTTP 请求,由 Nginx 负责请求的分发和跳转。
这种架构存在很多问题:Nginx 作为中间层,在配置文件中耦合了服务调用的逻辑,这削弱了微服务的完整性,也使得 Nginx 在一定程度上变成了一个重量级的 ESB。图 1 标识出了 Nginx 的转发信息流走向。
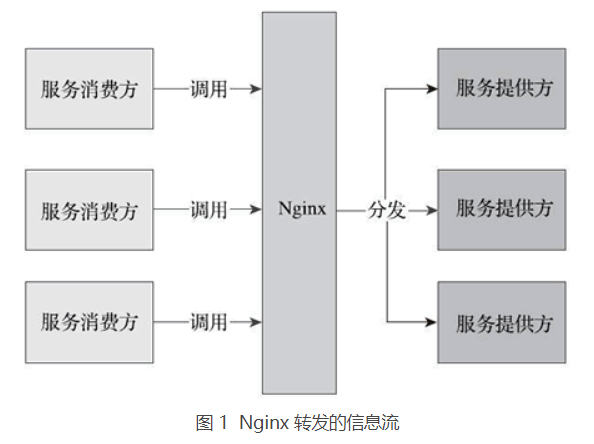
服务的信息分散在各个系统,无法统一管理和维护。每一次的服务调用都是一次尝试,服务消费方并不知道有哪些实例在给他们提供服务。这带来了一些问题:
- 无法直观地看到服务提供方和服务消费方当前的运行状况与通信频率;
- 消费方的失败重发、负载均衡等都没有统一策略,这加大了开发每个服务的难度,不利于快速演化。
为了解决上面的问题,我们需要一个现成的中心组件对服务进行整合,将每个服务的信息汇总,包括服务的组件名称、地址、数量等。
服务的调用方在请求某项服务时首先通过中心组件获取提供服务的实例信息(IP、端口等),再通过默认或自定义的策略选择该服务的某一提供方直接进行访问,所以考虑引入 Dubbo。
Dubbo 是阿里开源的一个 SOA 服务治理解决方案,文档丰富,在国内的使用度非常高。图 2 为 Dubbo 的基本架构图,使用 Dubbo 构建的微服务已经可以较好地解决上面提到的问题。
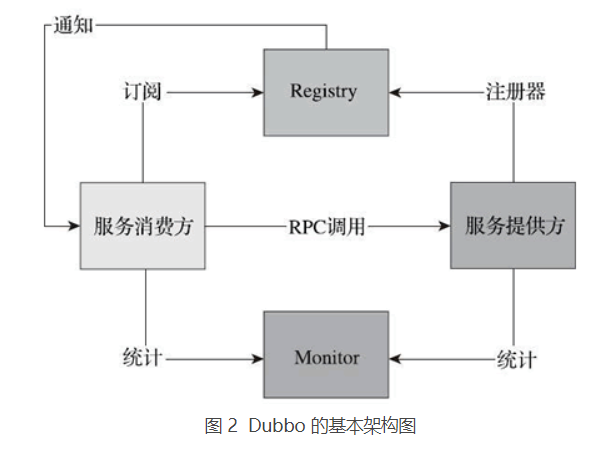
从图 2 中,可以看出以下几点:
- 调用中间层变成了可选组件,消费方可以直接访问服务提供方;
- 服务信息被集中到 Registry 中,形成了服务治理的中心组件;
- 通过 Monitor 监控系统,可以直观地展示服务调用的统计信息;
- 服务消费者可以进行负载均衡、服务降级的选择。
但是对于微服务架构而言,Dubbo 并不是十全十美的,也有一些缺陷,比如:
- Registry 严重依赖第三方组件(ZooKeeper 或者 Redis),当这些组件出现问题时,服务调用很快就会中断。
- Dubbo 只支持 RPC 调用。这使得服务提供方与调用方在代码上产生了强依赖,服务提供方需要不断将包含公共代码的 Jar 包打包出来供消费方使用。一旦打包出现问题,就会导致服务调用出错。
笔者认为,Dubbo 和 Spring Cloud 并不是完全的竞争关系,两者所解决的问题域并不一样。
Dubbo 的定位始终是一款 RPC 框架,而 Spring Cloud 的目标是微服务架构下的一站式解决方案。如果非要比较的话,Dubbo 可以类比到 Netflix OSS 技术栈,而 Spring Cloud 集成了 Netflix OSS 作为分布式服务治理解决方案,但除此之外 Spring Cloud 还提供了配置、消息、安全、调用链跟踪等分布式问题解决方案。
当前由于 RPC 协议、注册中心元数据不匹配等问题,在面临微服务基础框架选型时 Dubbo 与 Spring Cloud 只能二选一,这也是大家总是拿 Dubbo 和 Spring Cloud 做对比的原因之一。
Dubbo 已经适配到 Spring Cloud 生态,比如作为 Spring Cloud 的二进制通信方案来发挥 Dubbo 的性能优势,Dubbo 通过模块化以及对 HTTP 的支持适配到 Spring Cloud。
Spring Cloud 好在哪里
作为新一代的服务框架,Spring Cloud 提出的口号是开发“面向云的应用程序”,它为微服务架构提供了更加全面的技术支持。结合我们一开始提到的微服务的诉求,参见表 1,把Spring Cloud 与 Dubbo 进行一番对比。
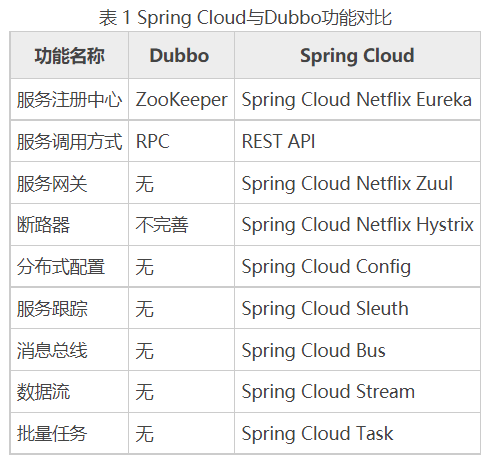
Spring Cloud 抛弃了 Dubbo 的 RPC 通信,采用的是基于 HTTP 的 REST 方式。严格来说,这两种方式各有优劣。虽然从一定程度上来说,后者牺牲了服务调用的性能,但也避免了上面提到的原生 RPC 带来的问题。而且 REST 相比 RPC 更为灵活,服务提供方和调用方,不存在代码级别的强依赖,这在强调快速演化的微服务环境下显得更加合适。
很明显,Spring Cloud 的功能比 Dubbo 更加强大,涵盖面更广,而且作为 Spring 的拳头项目,它也能够与 Spring Framework、Spring Boot、Spring Data、Spring Batch 等其他 Spring 项目完美融合,这些对于微服务而言是至关重要的。
前面提到,微服务背后一个重要的理念就是持续集成、快速交付,而在服务内部使用一个统一的技术框架,显然比将分散的技术组合到一起更有效率。
更重要的是,相比于 Dubbo,它是一个正在持续维护的、社区更加火热的开源项目,这就可以保证使用它构建的系统持续地得到开源力量的支持。
下面列举 Spring Cloud 的几个优势。
- Spring Cloud 来源于 Spring,质量、稳定性、持续性都可以得到保证。
- Spirng Cloud 天然支持 Spring Boot,更加便于业务落地。
- Spring Cloud 发展得非常快,从开始接触时的相关组件版本为 1.x,到现在将要发布 2.x 系列。
- Spring Cloud 是 Java 领域最适合做微服务的框架。
相比于其他框架,Spring Cloud 对微服务周边环境的支持力度最大。对于中小企业来讲,使用门槛较低。
SpringCloud与Dubbo区别
1.注册的服务的区别
Dubbo是基于java接口及Hession2序列化的来实现传输的,Provider对外暴露接口,Consumer根据接口的规则调用。也就是Provider向Zookeeper注册的是接口信息,Consumer从Zookeeper发现的是接口的信息,通过接口的name,group,version来匹配调用。Consumer只关注接口是否匹配,而对此接口属于什么应用不关心。当然接口的注册信息里会包含应用的ip,hostname等。
SpringCloud的服务发现是基于Http协议来实现的,Provider对外暴露的是应用信息,比如应用名称,ip地址等等,Consumer发现的是应用的信息,当调用的时候随机选择一个Provider的IP地址,应用名称,然后依据Http协议发送请求。Consumer关注的是应用名称,根据应用名称来决定调用的是哪个服务集群,然后对此名称对应的服务集群做负载均衡。Provider接受到请求后,根据内置的SpringMVC来匹配路由处理请求。
2. Server集群服务信息同步的区别
Dubbo使用Zookeeper做服务发现和治理,Zookeeper是一个分布式协调框架,其有很多很实用的功能,服务发现仅仅是其中的一个。Zookeeper基于著名的CAP理论中的C(一致性),P(分区可用性)实现,它的ZAB(zookeeper atomic broadcast protocol)协议,保证了集群里状态的一致性。Client的每一个事务操作都由Leader广播给所有Follower,当超过半数的Follower都返回执行成功后,才执行事务的ack。对于因网络崩溃或者宕机等问题而执行失败的zookeeper节点,zookeeper会基于zab的崩溃恢复机制来处理,这里不再讲述。每一个操作都需要过半数的zookeeper节点执行成功才确认成功,那么当zookeeper集群过半数节点出现问题时,服务发现功能就不可用。
SpringCloud使用Eureka做服务发现和治理,它是一个专门用于服务发现和治理的框架,其基于CAP理论中的A(可用性),P(分区可用性)实现。EurekaServer节点间的服务信息同步是基于异步Http实现的。每隔Server节点在接收Client的服务请求时,立即处理请求,然后将此次请求的信息拷贝,封装成一个Task,存入Queue中。Server初始化时会启动一个线程定期的从TaskQueue中批量提取Task,然后执行。服务同步不保证一定成功,虽然有失败重试,但超过一定时限后就放弃同步。当然其有一个特性,当服务丢失后,同步的操作返回400,404后会立即将最新的服务信息同步过去,因此即使中途同步失败,不会对后续的同步有影响。
3. 服务更新机制的区别
Dubbo使用Zookeeper做服务发现和治理,订阅Zookeeper下相应的znode。当节点发生变化,比如有新的元素增加,或者旧的元素移除,Zookeeper会通知所有订阅此节点的Client,将当前的全量数据同步给各Client,Dubbo里根据最新的数据来做相应处理,移除下线的,初始化新增的。每次更新都同步全量数据。
Eureka在启动时向Server进行一次全量拉取,获取所有的可用服务信息,之后默认情况下都是进行增量拉取。Server会将有变化的服务信息放在一个Queue里,Client每次同步时仅获取增量信息,根据信息里的操作类型,服务信息来对当前持有的服务做相应的处理,移除下线的,初始化新增的等。每次更新仅同步增量数据,也就是更新的数据。
4. 服务更新反馈机制的区别
Dubbo订阅Zookeeper下相应的节点,当节点的状态发生改变时,Zookeeper会立即反馈订阅的Client,实时性很高。
Eureka Server在接收到Client的更新操作,或者移除服务信息时,仅仅会将更新消息存放入recentlyChangedQueue中,不会主动的反馈其他Client。其他Client只有在拉取服务增量信息时才会感知到某个服务的更新,延时最大为30S,也就是拉取周期。
5. 服务信息回收机制的区别
Dubbo Provider初始化时会创建一个Zookeeper Client,专门用于与Zookeeper集群交互。维持与集群间的长连接,定时发送心跳,维护Zookeeper上自身节点的存在。节点类型是临时节点,也就是当心跳超时或者长连接断开时,会立即移除Provider对应的节点。
Dubbo Consumer初始化时也会创建一个Zookeeper Client,专门用于与Zookeeper集群交互。维持长连接,创建EvenetListener,监听Provider节点的变动情况。当Provider节点新增或者移除时,Zookeeper会广播这个事件,然后将此节点的当前值(剩下的所有接口信息)发送给那些注册了此节点监听器的Client。Consumer获取到对应Provider节点下的所有接口信息后,移除已下线的,创建新增的。
Zookeeper对服务信息的维护实时性和一致性比较高,但也可能因为网络问题或者集群问题导致服务不可用。
SpringCloud的服务信息回收仅基于心跳超时,与长连接无关。当心跳超时后,EurekaServer回收服务信息,然后将此动作同步给其他Server节点。当然可能一个服务信息会存在多个Server上,多次回收操作的同步具备幂等性。也就是说服务回收只需要通知一个Server节点就可以了,回收动作会通过Server节点传播开来。EurekaServer能够回收服务信息由个重要前提:上一分钟内正常发送心跳的服务的比列超过总数的85%,如果因为网络波动等原因造成大量服务的心跳超时,那么EurekaServer会触发自我保护机制,放弃回收那些心跳超时的服务信息。服务发现组件应该优先保证可用性,Consumer能够发现Provider,即使发现的是非可用的Provider,但因为Conusmer一般具备容错机制,不会对服务的正常调用有太多影响。从这点上看Eureka的服务发现机制要比Zookeeper稍微合理一点的。
6. 节点性质的区别
Dubbo只有Consumer订阅Provider节点,也就是Consumer发现Provider节点信息
Eureka不区分Consumer或者Provider,两者都统称为Client,一个Client内可能同时含有Provider,Consumer,通过服务发现组件获取的是其他所有的Client节点信息,在调用时根据应用名称来筛选节点
7. 使用方式的区别
Dubbo使用Zookeeper作为服务发现和治理的组件,所以需要搭建Zookeeper集群作为依赖。
SpringCloud使用Eureka作为服务发现和治理组件,在Spring应用中整合Eureka还是很简单的,引入依赖,加个注解,指定集群Server的serviceUrl,其他的都可以使用默认配置即可,启动应用,Eureka集群就搭建好了。同时配合SpringCloudConfg,能够统一管理Eureka的集群配置信息,可以动态的增加或减少EurekaServer的集群节点。Eurerka会每隔15分钟根据配置上的集群信息重新生成集群节点,覆盖之前的。这种机制比Zookeeper要更优秀一些,毕竟Eureka算是Spring生态里的一环,已经被整合的非常好了,能够以很多匪夷所思的方式来使用。