





Kafka 数据丢失和数据重复的原因和解决办法
Kafka的一些问题以及解决方法
数据丢失的原因
Kafka 消息发送分同步 (sync)、异步 (async) 两种方式,默认使用同步方式,可通过 producer.type 属性进行配置;
通过 request.required.acks 属性进行配置:值可设为 0, 1, -1(all) -1 和 all 等同
0 代表:不等待 broker 的 ack,这一操作提供了一个最低的延迟,broker 一接收到还没有写入磁盘就已经返回,当 broker 故障时有可能丢失数据;
1 代表:producer 等待 broker 的 ack,partition 的 leader 落盘成功后返回 ack,如果在 follower 同步成功之前 leader 故障,那么将会丢失数据;
-1 代表:producer 等待 broker 的 ack,partition 的 leader 和 follower 全部落盘成功后才返回 ack,数据一般不会丢失,延迟时间长但是可靠性高;但是这样也不能保证数据不丢失,比如当 ISR 中只有 leader 时( ISR 中的成员由于某些情况会增加也会减少,最少就只剩一个 leader),这样就变成了 acks = 1 的情况;
另外一个就是使用高级消费者存在数据丢失的隐患: 消费者读取完成,高级消费者 API 的 offset 已经提交,但是还没有处理完成Spark Streaming 挂掉,此时 offset 已经更新,无法再消费之前丢失的数据. 解决办法使用低级消费者。
数据重复的原因
acks = -1 的情况下,数据发送到 leader 后 ,部分 ISR 的副本同步,leader 此时挂掉。比如 follower1 和 follower2 都有可能变成新的 leader, producer 端会得到返回异常,producer 端会重新发送数据,数据可能会重复。
另外, 在高阶消费者中,offset 采用自动提交的方式, 自动提交时,假设 1s 提交一次 offset 的更新,设当前 offset = 10,当消费者消费了 0.5s 的数据,offset 移动了 15,由于提交间隔为 1s,因此这一 offset 的更新并不会被提交,这时候我们写的消费者挂掉,重启后,消费者会去 ZooKeeper 上获取读取位置,获取到的 offset 仍为10,它就会重复消费. 解决办法使用低级消费者。
数据丢失的解决办法
设置同步模式, producer.type = sync, Request.required.acks = -1, replication.factor >= 2 且 min.insync.replicas >= 2
数据重复的解决办法
这里需要 HW ( HighWartermark ) 的协同配合。类似于木桶原理,水位取决于最低那块短板
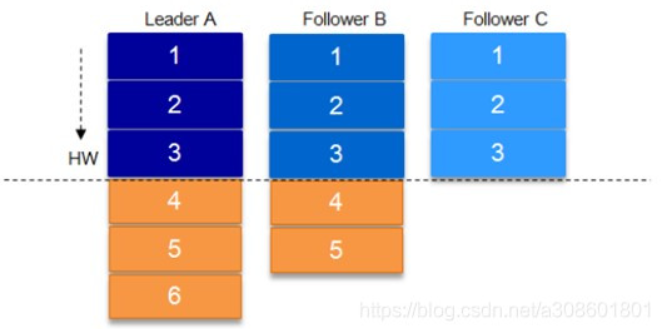
某个 topic 的某 partition 有三个副本,分别为 A、B、C。A 作为 leader 肯定是 LEO 最高,B 紧随其后,C 机器由于配置比较低,网络比较差,故而同步最慢。这个时候 A 机器宕机,这时候如果 B 成为 leader,假如没有 HW,在 A 重新恢复之后会做同步(makeFollower) 操作,在宕机时 log 文件之后直接做追加操作,而假如 B 的 LEO 已经达到了 A 的 LEO,会产生数据不一致的情况
解决办法就是: A 在做同步操作的时候,先将 log 文件截断到之前自己的 HW 的位置,即 3,之后再从 B 中拉取消息进行同步。