





Spring通过set注入解决循环依赖
循环依赖是指两个bean相互依赖,如下面的A和B: A依赖于B,B又依赖于A.如果未加处理这会导致无限递归程序崩溃,然而在实例项目中这种情况循环依赖的情况并不少见.为此Spring做了一些努力,解决了setter注入方式的循环依赖,对于构造器注入方式的循环只能检测并提前崩溃.
前言
1 | //setter注入方式的循环依赖 |
1 | //构造器注入方式的循环依赖 |
本文将简述Spring是如何支持setter注入方式的循环依赖的,并解释为何对构造器注入方式的循环依赖无能为力.
两种方式下bean的创建流程

在setter注入方式下的详细流程为:
- 实例化: 调用bean的无参构建函数生成实例.
- 注入依赖属性: 从容器中获取该bean依赖属性的实例(如果没有,进入依赖属性对应bean的创建流程),进行注入.
- 初始化: 如果bean实现了InitializingBean或@PostConstruct形式的初始化方法,进行调用
在构造器注入方式下的详细流程为
获取依赖属性&实例化: 在容器中找到有参构造器中声明的参数的实例((如果没有,进入依赖属性对应bean的创建流程)),并用这些这些参数调用这个构造函数生成实例
初始化: 同setter注入
构造器注入无法解决循环依赖的原因
构造器注入必须先获取依赖属性才能完成实例化,这是其无法解决循环依赖的根本原因.用上面的例子说明:
- 开始创建A
- 获取A的依赖属性b对应的实例B,发现还没有,开始创建B
- 获取B的依赖属性a对应的实例A,发现它正在创建中(无法获取到A的实例),Spring检测到这一点立刻报错,提示发生无法解决的循环依赖.
setter注入解决循环依赖的方式
setter注入下实例化和依赖属性注入是分开的,这是其可以解决循环依赖的根本原因,还用上面的例子说明
- 开始创建A
- 调用A的无参构造函数实例化A,把A存放在某个地方X,标识它是一个尚不完备但是可获取的bean
- 开始注入A的属性,获取A的依赖属性发现b对应的实例B还没创建,开始创建B
- 与2类似,调用B的无参构造函数实例化B,把B存放在某个地方X,标识它是一个尚不完备但是可获取的bean
- 开始注入B的属性,获取B的依赖属性发现b对应的实例B还没在容器但是在X已经有了,就从X中获取到a,B的注入完成
- 完成B的初始化,放到容器中.
- 返回B,给到步骤3,A的注入完成
- 完成A的初始化,放到容器中.
流程如下图:
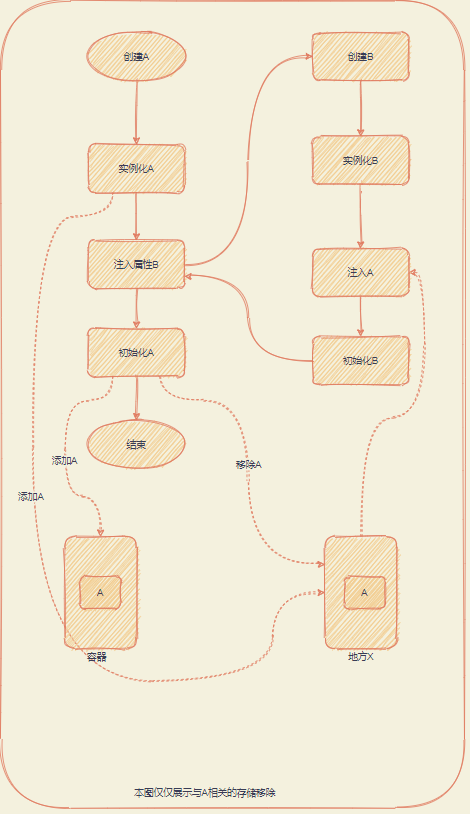
setter方式解决循环依赖的核心就是提前将仅完成实例化的bean暴露出来,提供给其他bean,这个暴露的地方就是图中的地方X,
这个地方X,在Spring代码中,对应的是DefaultSingletonBeanRegistry的两个属性
1 | /** Cache of singleton factories: bean name to ObjectFactory. */ |
singletonFactories存储的是生成bean的工厂,工厂签名如下及添加逻辑如下
1 | public interface ObjectFactory<T> { |
earlySingletonObjects存储的则是从这个工厂生成的bean.
1 | //DefaultSingletonBeanRegistry |
到这里,setter注入方式解决循环依赖的原因就已经搞清楚了.但是我还有一个疑问,为什么要在两个对象,而非直接用earlySingletonObjects存储getEarlyBeanReference生成的对象呢?,再次翻阅源码后,我的结论如下:
getEarlyBeanReference是一个相对耗时的操作,(生成代理,mock都不是简单操作),它仅在发生循环依赖的情况下被调用,而大部分bean不会有循环依赖存在,也就不会调用到getEarlyBeanReference,进而节省资源.
后记
本文解析了Spring是如何支持setter注入方式的循环依赖,其核心就是提前暴露出不完备的bean供其他bean使用.