





分布式系统唯一ID生成方案
在互联网的业务系统中,涉及到各种各样的ID,如在支付系统中就会有支付ID、退款ID等。那一般生成ID都有哪些解决方案呢?特别是在复杂的分布式系统业务场景中,我们应该采用哪种适合自己的解决方案是十分重要的。下面我们一一来列举一下,不一定全部适合,这些解决方案仅供你参考,或许对你有用。
分布式ID的特性
- 唯一性:确保生成的ID是全网唯一的。
- 有序递增性:确保生成的ID是对于某个用户或者业务是按一定的数字有序递增的。
- 高可用性:确保任何时候都能正确的生成ID。
- 带时间:ID里面包含时间,一眼扫过去就知道哪天的交易。
分布式ID的生成方案
1. UUID
核心思想:结合机器的网卡(基于名字空间/名字的散列值MD5/SHA1)、当地时间(基于时间戳&时钟序列)、一个随记数来生成UUID。
其结构如下:
aaaaaaaa-bbbb-cccc-dddd-eeeeeeeeeeee(即包含32个16进制数字,以连字号-分为五段,最终形成“8-4-4-4-12”的36个字符的字符串,即32个英数字母+4个连字号)。例如:550e8400-e29b-41d4-a716-446655440000
优点:
① 本地生成,没有网络消耗,生成简单,没有高可用风险。
缺点:
① 不易于存储:UUID太长,16字节128位,通常以36长度的字符串表示,很多场景不适用。
② 信息不安全:基于MAC地址生成UUID的算法可能会造成MAC地址泄露,这个漏洞曾被用于寻找梅丽莎病毒的制作者位置。
③ 无序查询效率低:由于生成的UUID是无序不可读的字符串,所以其查询效率低。
2. 数据库自增ID
核心思想:使用数据库的id自增策略(如: Mysql的auto_increment)。
优点:
① 简单,天然有序。
缺点:
① 并发性不好。
② 数据库写压力大。
③ 数据库故障后不可使用。
④ 存在数量泄露风险。
针对以上缺点,有以下几种优化方案:
- 数据库水平拆分,设置不同的初始值和相同的自增步长
- 核心思想:将数据库进行水平拆分,每个数据库设置不同的初始值和相同的自增步长。
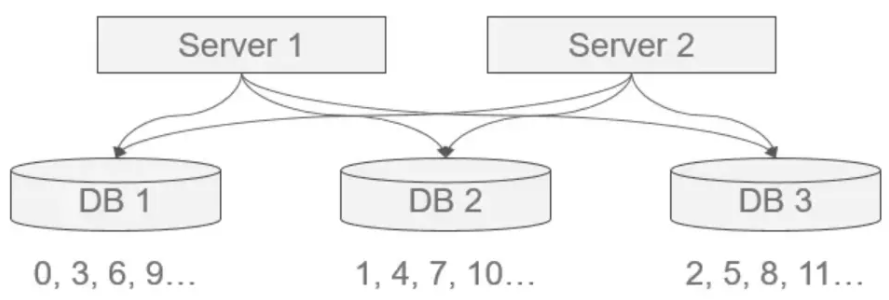
如图所示,可保证每台数据库生成的ID是不冲突的,但这种固定步长的方式也会带来扩容的问题,很容易想到当扩容时会出现无ID初始值可分的窘境,解决方案有:
① 根据扩容考虑决定步长。
② 增加其他位标记区分扩容。
这其实都是在需求与方案间的权衡,根据需求来选择最适合的方式。
3. 批量缓存自增ID
核心思想:如果使用单台机器做ID生成,可以避免固定步长带来的扩容问题(方案1的缺点)。
具体做法是:每次批量生成一批ID给不同的机器去慢慢消费,这样数据库的压力也会减小到N分之一,且故障后可坚持一段时间。
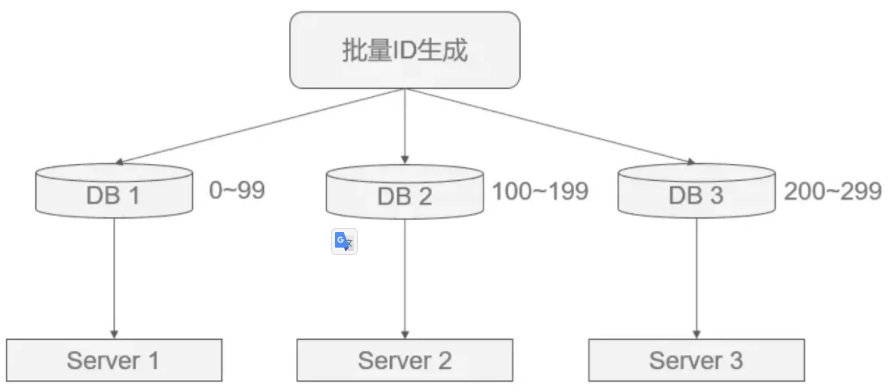
如图所示,但这种做法的缺点是服务器重启、单点故障会造成ID不连续。
4. Redis生成ID
Redis的所有命令操作都是单线程的,本身提供像 incr 和 increby 这样的自增原子命令,所以能保证生成的 ID 肯定是唯一有序的。
优点:不依赖于数据库,灵活方便,且性能优于数据库;数字ID天然排序,对分页或者需要排序的结果很有帮助。
缺点:如果系统中没有Redis,还需要引入新的组件,增加系统复杂度;需要编码和配置的工作量比较大。
考虑到单节点的性能瓶颈,可以使用 Redis 集群来获取更高的吞吐量。假如一个集群中有5台 Redis。可以初始化每台 Redis 的值分别是1, 2, 3, 4, 5,然后步长都是 5。各个 Redis 生成的 ID 为:
1 | A:1, 6, 11, 16, 21 |
随便负载到哪个机确定好,未来很难做修改。步长和初始值一定需要事先确定。使用 Redis 集群也可以方式单点故障的问题。
另外,比较适合使用 Redis 来生成每天从0开始的流水号。比如订单号 = 日期 + 当日自增长号。可以每天在 Redis 中生成一个 Key ,使用 INCR 进行累加。
5. Twitter的snowflake算法
Twitter 利用 zookeeper 实现了一个全局ID生成的服务 Snowflake:https://github.com/twitter/snowflake
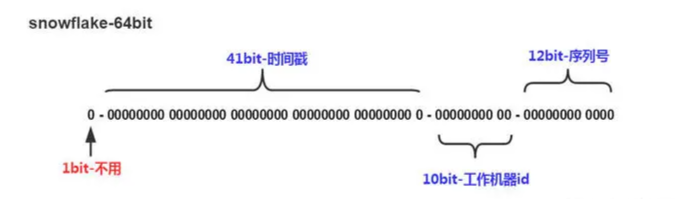
如上图的所示,Twitter 的 Snowflake 算法由下面几部分组成:
- 1位符号位:
由于 long 类型在 java 中带符号的,最高位为符号位,正数为 0,负数为 1,且实际系统中所使用的ID一般都是正数,所以最高位为 0。
- 41位时间戳(毫秒级):
需要注意的是此处的 41 位时间戳并非存储当前时间的时间戳,而是存储时间戳的差值(当前时间戳 - 起始时间戳),这里的起始时间戳一般是ID生成器开始使用的时间戳,由程序来指定,所以41位毫秒时间戳最多可以使用 (1 << 41) / (1000x60x60x24x365) = 69年。
- 10位数据机器位:
包括5位数据标识位和5位机器标识位,这10位决定了分布式系统中最多可以部署 1 << 10 = 1024 s个节点。超过这个数量,生成的ID就有可能会冲突。
- 12位毫秒内的序列:
这 12 位计数支持每个节点每毫秒(同一台机器,同一时刻)最多生成 1 << 12 = 4096个ID
加起来刚好64位,为一个Long型。
- 优点:高性能,低延迟,按时间有序,一般不会造成ID碰撞
- 缺点:需要独立的开发和部署,依赖于机器的时钟
简单实现
1 | public class IdWorker { |
6. 百度UidGenerator
UidGenerator是百度开源的分布式ID生成器,基于于snowflake算法的实现,看起来感觉还行。不过,国内开源的项目维护性真是担忧。
具体可以参考官网说明:https://github.com/baidu/uid-generator/blob/master/README.zh_cn.md
7. 美团Leaf
Leaf 是美团开源的分布式ID生成器,能保证全局唯一性、趋势递增、单调递增、信息安全,里面也提到了几种分布式方案的对比,但也需要依赖关系数据库、Zookeeper等中间件。
具体可以参考官网说明:https://tech.meituan.com/MT_Leaf.html