





7种阻塞队列
队列:FIFO(先进先出)的数据结构即为队列
阻塞队列:操作会被阻塞的队列即为阻塞队列, 在java中 BlockingQueue 接口在 Queue 接口的基础上增加了两组阻塞方法, offer(e,time) put , poll(time) take()
7种阻塞队列
- 有界: 在创建队列时必须或允许指定队列大小, 允许调用抛出异常的 add 方法
- 无界: 在创建队列时无需或不可以指定队列大小, 无限制的插入 add = offer 操作
阻塞队列的几个操作方法
| 抛出异常 | 特殊值 | 阻塞 | 超时 | |
|---|---|---|---|---|
| 插入 | add(e) | offer(e) | put(e) | offer(e,time,unit) |
| 移除 | remove() | poll() | take() | poll(time,unit) |
| 检查 | element() | peek() | 不可用 | 不可用 |
1. ArrayBlockingQueue[有界]
一个使用数组实现的有界阻塞队列. 创建队列时必须给定队列大小, 同时可以通过创建队列的时候设置公平访问(通过重入锁的公平访问实现)
1 | public ArrayBlockingQueue(int capacity, boolean fair) { |
元素达到队列容量上限时再入队
根据调用不同的方法, 返回不同的状态
add 方法将抛出异常
1 | public boolean add(E e) { |
offer 方法将返回 false
1 | public boolean offer(E e) { |
put 方法将无限时阻塞
1 | public void put(E e) throws InterruptedException { |
offer(E e, long timeout, TimeUnit unit) 将超时阻塞
1 | public boolean offer(E e, long timeout, TimeUnit unit) |
队列为空时获取元素时
poll 方法返回空
1 | public E poll() { |
take 将无限时阻塞
1 | public E take() throws InterruptedException { |
poll(long timeout, TimeUnit unit) 超时阻塞
1 | public E poll(long timeout, TimeUnit unit) throws InterruptedException { |
总结
- 数组有界队列
- 可加入公平策略
- 插入时提供了可抛出异常操作
- 插入元素不能为空
该队列模式适合在需要公平访问的场景下使用, 若无公平性要求该队列个人拙见不建议使用, 因操作数组和公平性原因,其吞吐量较低
2. LinkedBlockingQueue[有界]
一个使用链表实现的有界队列
1 | public LinkedBlockingQueue(int capacity) { |
如果不指定大小, 默认值为 int 的最大值
1 | public LinkedBlockingQueue() { |
元素达到队列容量上限时再入队
队列为空时获取元素时
与 [ArrayBlockingQueue](#1. ArrayBlockingQueue[有界]) 相同
总结:
- 结论不指定队列大小, 默认值为 int 最大值
- 吞吐量要比ArrayBlockingQueue高
- 链表有界队列
- 不可加入公平策略
- 插入时提供了可抛出异常操作
- 插入元素不能为空
3. LinkedBlockingDeque[有界]
通过链表实现的一个双端阻塞队列(LikedBlockingQueue增加了队尾的操作)
该队列增加了一组队首队尾的操作方法
1 | add -> addFirst(push)/addLast |
增加类(add/put/offer) 原方法调用与其调用相同前缀last方法操作相同
例: add = addLast ; put = putLast
获取类(peek/poll/element) 原方法调用与其调用相同前缀first方法操作相同
例: peek = peekFirst; poll = peekFirst
元素达到队列容量上限时再入队
add 方法在队列容量达到最大值时抛出异常 throw new IllegalStateException(“Deque full”);
队列为空时获取元素时
element/getFirst/getLast 方法在队列为空时抛出异常 if (x == null) throw new NoSuchElementException();
总结:
- 如果创建队列时不指定队列大小, 默认值为 int 最大值
- 吞吐量要比LinkedBlockingQueue高
- 链表有界双端队列
- 不可加入公平策略
- 插入时提供了可抛出异常操作
- 插入元素不能为空
- 可以通过队首队尾插入或取出元素
4. LinkedTransferQueue[无界]
一个由链表实现的无界转换队列, 相对 [LinkedBlockingQueue](#2. LinkedBlockingQueue[有界]) 增加了几个方法
1.transfer(E e)
等待消费者调用返回
向队列的调用阻塞者直接提供元素, 如果没有人来获取, 则将这个元素放入队尾, 当这个元素出队的时候返回, 否则一直阻塞
2.tryTransfer(E e)
调用一次即返回
尝试向队列的调用阻塞者直接提供元素, 立即返回false or true, 提供的元素不入队.
3.tryTransfer(E e, long timeout, TimeUnit unit)
等待消费者调用返回, 一定时间内等不到亦返回
在 tryTransfer 的基础上加入了时间, 在给定时间内尝试
如果有阻塞调用者直接调用该队列的take 或者 poll(time) 方法, 阻塞状态下返回该值
如果未有阻塞调用者调用, 将元素放入队尾, 当在给定时间内被调用 返回 true, 如果在给定时间内未被调用, 返回false 且元素从队列中移除.
总结:
- 创建时无需指定队列大小, 且无最大值即无阻塞插入知道内存溢出
- 吞吐量要比LinkedBlockingQueue高
- 链表无界队列
- 在调用队列元素被阻塞时, 提供了可以将入队元素直接返回的 transfer方法
- 插入元素不能为空
5. PriorityBlockingQueue[无界]
一个使用数组 + 比较器实现的优先级队列
这个队列使用了二叉堆排序的方式来实现优先级
关于这个队列的重点内容也是在二叉堆排序上, 这里延伸的内容还是比较多的, 堆结构, 二叉堆, 堆排序, 选择排序…
总结:
- 如果创建队列时不指定队列大小, 默认值为 11, 超出时不会阻塞而是扩容(当扩容超过 int 最大值 - 8 时将抛出堆内存溢出异常) 每次扩容为当前队列大小的 50%
- 数组无界队列(最大长度 int最大值 - 8)
- 如果指定了比较器, 则必须指定大小
- 插入元素不能为空
6. DelayQueue[无界]
使用 PriorityQueue 实现的一个无界延迟队列, 使用这个队列需要自己实现一些内容, 包括延迟配置、比较器的实现。该队列可以用于定时任务调度,周期任务调度
当你需要指定元素的优先级,执行的时机,那这个队列即是不二之选。
总结:
- 元素存储使用的 priorityqueue
- 可以指定元素的访问延迟时间及优先级
- 插入元素不能为空
7. SynchronousQueue[无容量]
dual queue + dual stack 双队列 + 双栈实现
这个队列也是一个比较特殊的队列, 在 JDK 1.6的时候改写了底层实现, 就是用了上面提到的方法.
这个队列是一个没有容量的队列,所以在调用方法上有一些不同。
add 方法将会抛出一个 java.lang.IllegalStateException: Queue full异常
offer 方法会返回false
put 方法将会被阻塞
调用出队方法也会有一些问题
poll 方法返回null
take 方法将被阻塞
同步执行入队和出队即可, 这也是为什么该队列是吞吐量最高的队列原因
总结:
- 没有容量
- 吞吐量要比ArrayBlockingQueue与LinkedBlockingQueue高
- 可加入公平策略
- 插入时提供了可抛出异常操作
- 插入元素不能为空
8、一些问题
线程池中为什么要使用阻塞队列?
在线程池中活跃线程数达到corePoolSize时,线程池将会将后续的task提交到BlockingQueue中,为什么这样设计呢?
在一个task提交到线程池时,假设可以被线程池中的一个线程执行,则进行以下过程:
exeute —> addWorker(Runnable command, boolean core)—> workers.add(w),启动线程执行任务(获取全局锁ReentrantLock mainLock)
具体源码如下:
1 | public void execute(Runnable command) { |
1 | private boolean addWorker(Runnable firstTask, boolean core){ |
上述代码中:
1 | w = new Worker(firstTask); |
Worker实现了Runnable接口,里面定义了一个final变量Thread thread
Worker的构造函数为:
1 | Worker(Runnable firstTask) { |
run函数为:
1 | public void run() { |
1 | final void runWorker(Worker w) { |
看完上述代码后,我们可以得出:
线程池创建线程需要获取mainlock这个全局锁,影响并发效率,阻塞队列可以很好的缓冲。
另外一方面,如果新任务的到达速率超过了线程池的处理速率,那么新到来的请求将累加起来,这样的话将耗尽资源。
阻塞队列的特点
阻塞队列区别于其他类型的队列的最主要的特点就是“阻塞”这两个字,阻塞功能使得生产者和消费者两端的能力得以平衡,当有任何一端速度过快时,阻塞队列便会把过快的速度给降下来。实现阻塞最重要的两个方法是 take 方法和 put 方法
take 方法
take 方法的功能是获取并移除队列的头结点,通常在队列里有数据的时候是可以正常移除的。可是一旦执行 take 方法的时候,队列里无数据,则阻塞,直到队列里有数据。 一旦队列里有数据了,就会立刻解除阻塞状态,并且取到数据。过程如图所示:

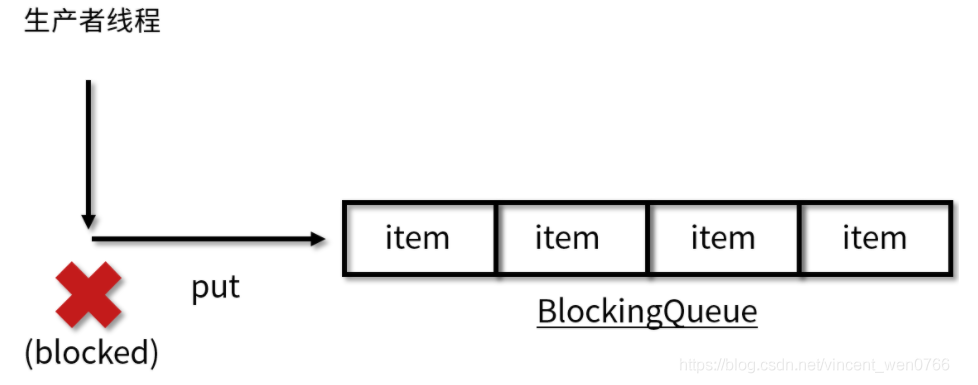
put 方法
put 方法插入元素时,如果队列没有满,那就和普通的插入一样是正常的插入,但是如果队列已满,那么就无法继续插入,则阻塞,直到队列里有了空闲空间。如果后续队列有了空闲空间,比如消费者消费了一个元素,那么此时队列就会解除阻塞状态,并把需要添加的数据添加到队列中。过程如图所示:
是否有界(容量有多大)
阻塞队列还有一个非常重要的属性,那就是容量的大小,分为有界和无界两种
无界队列意味着里面可以容纳非常多的元素,例如 LinkedBlockingQueue 的上限是 Integer.MAX_VALUE,约为 2 的 31 次方,是非常大的一个数,可以近似认为是无限容量,因为我们几乎无法把这个容量装满
有的阻塞队列是有界的,例如 ArrayBlockingQueue 如果容量满了,也不会扩容,所以一旦满了就无法再往里放数据了。