





Java序列化与反序列化
一些问题
Java序列化,反序列化
序列化指将Java对象转换为字节序列的过程。
反序列化指将字节序列转换为目标对象的过程;
为什么要序列化?
其实序列化最终的目的是为了对象可以跨平台存储,和进行网络传输。而我们进行跨平台存储和网络传输的方式就是IO,而我们的IO支持的数据格式就是字节数组。
因为我们单方面的只把对象转成字节数组还不行,因为没有规则的字节数组我们是没办法把对象的本来面目还原回来的,所以我们必须在把对象转成字节数组的时候就制定一种规则 (序列化) ,那么我们从IO流里面读出数据的时候再以这种规则把对象还原回来 (反序列化)。
如果我们要把一栋房子从一个地方运输到另一个地方去,序列化就是我把房子拆成一个个的砖块放到车子里,然后留下一张房子原来结构的图纸,反序列化就是我们把房子运输到了目的地以后,根据图纸把一块块砖头还原成房子原来面目的过程。
什么情况下需要序列化?
当Java对象需要网络传输或者持久化到磁盘上时;
通过上面我想你已经知道了凡是需要进行 “跨平台存储”和”网络传输” 的数据,都需要进行序列化。
本质上存储和网络传输 都需要经过 把一个对象状态保存成一种跨平台识别的字节格式,然后其他的平台才可以通过字节信息解析还原对象信息。
序列化的实现方式?
1.Serializable 接口
一个对象想要被序列化,那么它的类就要实现此接口或者它的子接口。
这个对象的所有属性(包括private属性、包括其引用的对象)都可以被序列化和反序列化来保存、传递。不想序列化的字段可以使用transient修饰。
由于Serializable对象完全以它存储的二进制位为基础来构造,因此并不会调用任何构造函数,因此Serializable类无需默认构造函数,但是当Serializable类的父类没有实现Serializable接口时,反序列化过程会调用父类的默认构造函数,因此该父类必需有默认构造函数,否则会抛异常。
使用transient关键字阻止序列化虽然简单方便,但被它修饰的属性被完全隔离在序列化机制之外,导致了在反序列化时无法获取该属性的值,而通过在需要序列化的对象的Java类里加入writeObject()方法与readObject()方法可以控制如何序列化各属性,甚至完全不序列化某些属性或者加密序列化某些属性。
2.Externalizable 接口
它是Serializable接口的子类,用户要实现的writeExternal()和readExternal() 方法,用来决定如何序列化和反序列化。
因为序列化和反序列化方法需要自己实现,因此可以指定序列化哪些属性,而transient在这里无效。
对Externalizable对象反序列化时,会先调用类的无参构造方法,这是有别于默认反序列方式的。如果把类的不带参数的构造方法删除,或者把该构造方法的访问权限设置为private、默认或protected级别,会抛出java.io.InvalidException: no valid constructor异常,因此Externalizable对象必须有默认构造函数,而且必需是public的。
对比
使用时,你只想隐藏一个属性,比如用户对象user的密码pwd,如果使用Externalizable,并除了pwd之外的每个属性都写在writeExternal()方法里,这样显得麻烦,可以使用Serializable接口,并在要隐藏的属性pwd前面加上transient就可以实现了。如果要定义很多的特殊处理,就可以使用Externalizable。
当然这里我们有一些疑惑,Serializable 中的writeObject()方法与readObject()方法科可以实现自定义序列化,而Externalizable 中的writeExternal()和readExternal() 方法也可以,他们有什么异同呢?
- readExternal(),writeExternal()两个方法,这两个方法除了方法签名和readObject(),writeObject()两个方法的方法签名不同之外,其方法体完全一样。
- 需要指出的是,当使用Externalizable机制反序列化该对象时,程序会使用public的无参构造器创建实例,然后才执行readExternal()方法进行反序列化,因此实现Externalizable的序列化类必须提供public的无参构造。
- 虽然实现Externalizable接口能带来一定的性能提升,但由于实现ExternaLizable接口导致了编程复杂度的增加,所以大部分时候都是采用实现Serializable接口方式来实现序列化。
3.各种序列化方式的对比

Java 序列化中如果有些字段不想进行序列化,怎么办?
对于不想进行序列化的变量,使用 transient 关键字修饰。
transient 关键字的作用是:阻止实例中那些用此关键字修饰的的变量序列化;当对象被反序列化时,被 transient 修饰的变量值不会被持久化和恢复。transient 只能修饰变量,不能修饰类和方法。
序列化技术选型的几个关键点
序列化协议各有千秋,不能简单的说一种序列化协议是最好的,只能从你的当时环境下去选择最适合你们的序列化协议,如果你要为你的公司项目进行序列化技术的选型,那么主要从以下几个因素。
协议是否支持跨平台
如果你们公司有好多种语言进行混合开发,那么就肯定不适合用有语言局限性的序列化协议,要不然你JDK序列化出来的格式,其他语言并没法支持。
序列化的速度
如果序列化的频率非常高,那么选择序列化速度快的协议会为你的系统性能提升不少。
序列化出来的大小
如果频繁的在网络中传输的数据那就需要数据越小越好,小的数据传输快,也不占带宽,也能整体提升系统的性能。
引言
将 Java 对象序列化为二进制文件的 Java 序列化技术是 Java 系列技术中一个较为重要的技术点,在大部分情况下,开发人员只需要了解被序列化的类需要实现 Serializable 接口,使用 ObjectInputStream 和 ObjectOutputStream 进行对象的读写。然而在有些情况下,光知道这些还远远不够,文章列举了笔者遇到的一些真实情境,它们与 Java 序列化相关,通过分析情境出现的原因,使读者轻松牢记 Java 序列化中的一些高级认识。
1. 序列化 ID 问题
情境: 两个客户端 A 和 B 试图通过网络传递对象数据,A 端将对象 C 序列化为二进制数据再传给 B,B 反序列化得到 C。
问题: C 对象的全类路径假设为 com.inout.Test,在 A 和 B 端都有这么一个类文件,功能代码完全一致。也都实现了 Serializable 接口,但是反序列化时总是提示不成功。
解决: 虚拟机是否允许反序列化,不仅取决于类路径和功能代码是否一致,一个非常重要的一点是两个类的序列化 ID 是否一致(就是 private static final long serialVersionUID = 1L) 。清单 1 中,虽然两个类的功能代码完全一致,但是序列化 ID 不同,他们无法相互序列化和反序列化。
清单 1. 相同功能代码不同序列化 ID 的类对比
1 | package com.inout; |
序列化 ID 在 Eclipse 下提供了两种生成策略,一个是固定的 1L,一个是随机生成一个不重复的 long 类型数据(实际上是使用 JDK 工具生成),在这里有一个建议,如果没有特殊需求,就是用默认的 1L 就可以,这样可以确保代码一致时反序列化成功。那么随机生成的序列化 ID 有什么作用呢,有些时候,通过改变序列化 ID 可以用来限制某些用户的使用。
特性使用案例
读者应该听过 Façade 模式【提供一组统一的接口,使子系统更易用,可以解决:1.易用性(封装底层数据,对外暴露简单接口);2.性能问题(需要访问3次的接口,用一个接口分装,解决交互性能问题);3.解决分布式事务问题 (一次请求需要两个模块操作共同成功,共同失败,直接封装到一个接口解决问题)】,它是为应用程序提供统一的访问接口,案例程序中的 Client 客户端使用了该模式,案例程序结构图如图 1 所示。
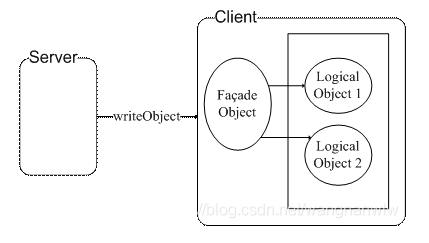
案例程序结构
Client 端通过 Façade Object 才可以与业务逻辑对象进行交互。而客户端的 Façade Object 不能直接由 Client 生成,而是需要 Server 端生成,然后序列化后通过网络将二进制对象数据传给 Client,Client 负责反序列化得到 Façade 对象。该模式可以使得 Client 端程序的使用需要服务器端的许可,同时 Client 端和服务器端的 Façade Object 类需要保持一致。当服务器端想要进行版本更新时,只要将服务器端的 Façade Object 类的序列化 ID 再次生成,当 Client 端反序列化 Façade Object 就会失败,也就是强制 Client 端从服务器端获取最新程序。
2. 静态变量序列化
情境 :查看清单 2 的代码。
清单 2. 静态变量序列化问题代码
1 | public class Test implements Serializable { |
清单 2 中的 main 方法,将对象序列化后,修改静态变量的数值,再将序列化对象读取出来,然后通过读取出来的对象获得静态变量的数值并打印出来。依照清单 2,这个 System.out.println(t.staticVar) 语句输出的是 10 还是 5 呢?
最后的输出是 10,对于无法理解的读者认为,打印的 staticVar 是从读取的对象里获得的,应该是保存时的状态才对。之所以打印 10 的原因在于序列化时,并不保存静态变量,这其实比较容易理解,序列化保存的是对象的状态,静态变量属于类的状态,因此 序列化并不保存静态变量 。
3. 父类的序列化与 Transient 关键字
情境: 一个子类实现了 Serializable 接口,它的父类都没有实现 Serializable 接口,序列化该子类对象,然后反序列化后输出父类定义的某变量的数值,该变量数值与序列化时的数值不同。
解决: 要想将父类对象也序列化,就需要让父类也实现 Serializable 接口 。如果父类不实现的话的,就 需要有默认的无参的构造函数 。在父类没有实现 Serializable 接口时,虚拟机是不会序列化父对象的,而一个 Java 对象的构造必须先有父对象,才有子对象,反序列化也不例外。所以反序列化时,为了构造父对象,只能调用父类的无参构造函数作为默认的父对象。因此当我们取父对象的变量值时,它的值是调用父类无参构造函数后的值。如果你考虑到这种序列化的情况,在父类无参构造函数中对变量进行初始化,否则的话,父类变量值都是默认声明的值,如 int 型的默认是 0,string 型的默认是 null。
Transient 关键字的作用是控制变量的序列化,在变量声明前加上该关键字,可以阻止该变量被序列化到文件中,在被反序列化后,transient 变量的值被设为初始值,如 int 型的是 0,对象型的是 null。
特性使用案例
我们熟悉使用 Transient 关键字可以使得字段不被序列化,那么还有别的方法吗?根据父类对象序列化的规则,我们可以将不需要被序列化的字段抽取出来放到父类中,子类实现 Serializable 接口,父类不实现,根据父类序列化规则,父类的字段数据将不被序列化,形成类图如图 2 所示。
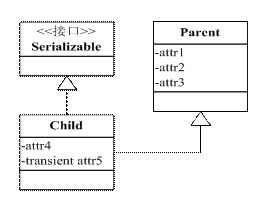
案例程序类图
上图中可以看出,attr1、attr2、attr3、attr5 都不会被序列化,放在父类中的好处在于当有另外一个 Child 类时,attr1、attr2、attr3 依然不会被序列化,不用重复抒写 transient,代码简洁。
4. 对敏感字段加密
情境: 服务器端给客户端发送序列化对象数据,对象中有一些数据是敏感的,比如密码字符串等,希望对该密码字段在序列化时,进行加密,而客户端如果拥有解密的密钥,只有在客户端进行反序列化时,才可以对密码进行读取,这样可以一定程度保证序列化对象的数据安全。
解决: 在序列化过程中,虚拟机会试图调用对象类里的 writeObject 和 readObject 方法,进行用户自定义的序列化和反序列化,如果没有这样的方法,则默认调用是 ObjectOutputStream 的 defaultWriteObject 方法以及 ObjectInputStream 的 defaultReadObject 方法。用户自定义的 writeObject 和 readObject 方法可以允许用户控制序列化的过程,比如可以在序列化的过程中动态改变序列化的数值。基于这个原理,可以在实际应用中得到使用,用于敏感字段的加密工作,清单 3 展示了这个过程。
清单 3. 静态变量序列化问题代码
1 | private static final long serialVersionUID = 1L; |
在清单 3 的 writeObject 方法中,对密码进行了加密,在 readObject 中则对 password 进行解密,只有拥有密钥的客户端,才可以正确的解析出密码,确保了数据的安全。执行清单 3 后控制台输出如图 3 所示。
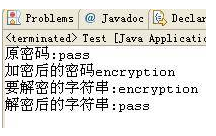
数据加密演示
特性使用案例
RMI 技术是完全基于 Java 序列化技术的,服务器端接口调用所需要的参数对象来至于客户端,它们通过网络相互传输。这就涉及 RMI 的安全传输的问题。一些敏感的字段,如用户名密码(用户登录时需要对密码进行传输),我们希望对其进行加密,这时,就可以采用本节介绍的方法在客户端对密码进行加密,服务器端进行解密,确保数据传输的安全性。
5. 序列化存储规则
情境 :问题代码如清单 4 所示。
清单 4. 存储规则问题代码
1 | ObjectOutputStream out = new ObjectOutputStream( |
清单 4 中对同一对象两次写入文件,打印出写入一次对象后的存储大小和写入两次后的存储大小,然后从文件中反序列化出两个对象,比较这两个对象是否为同一对象。一般的思维是,两次写入对象,文件大小会变为两倍的大小,反序列化时,由于从文件读取,生成了两个对象,判断相等时应该是输入 false 才对,但是最后结果输出如图 4 所示。
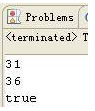
示例程序输出
我们看到,第二次写入对象时文件只增加了 5 字节,并且两个对象是相等的,这是为什么呢?
解答: Java 序列化机制为了节省磁盘空间,具有特定的存储规则,当写入文件的为同一对象时,并不会再将对象的内容进行存储,而只是再次存储一份引用,上面增加的 5 字节的存储空间就是新增引用和一些控制信息的空间。反序列化时,恢复引用关系,使得清单 3 中的 t1 和 t2 指向唯一的对象,二者相等,输出 true。该存储规则极大的节省了存储空间。
特性案例分析
查看清单 5 的代码。
清单 5. 案例代码
1 | ObjectOutputStream out = new ObjectOutputStream(new FileOutputStream("result.obj")); |
清单 5 的目的是希望将 test 对象两次保存到 result.obj 文件中,写入一次以后修改对象属性值再次保存第二次,然后从 result.obj 中再依次读出两个对象,输出这两个对象的 i 属性值。案例代码的目的原本是希望一次性传输对象修改前后的状态。
结果两个输出的都是 1, 原因就是第一次写入对象以后,第二次再试图写的时候,虚拟机根据引用关系知道已经有一个相同对象已经写入文件,因此只保存第二次写的引用,所以读取时,都是第一次保存的对象。读者在使用一个文件多次 writeObject 需要特别注意这个问题。