





InnoDB崩溃恢复机制
概述
数据库系统与文件系统大的区别在于数据库能保证操作的原子性,一个操作要么不做要么都做,即使在数据库宕机的情况下,也不会出现操作一半的情况,这个就需要数据库的日志和一套完善的崩溃恢复机制来保证。下面简单介绍一下InnoDB的崩溃恢复流程。
相关概念
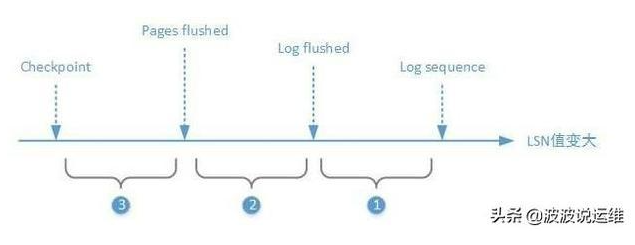
lsn: 可以理解为数据库从创建以来产生的redo日志量,这个值越大,说明数据库的更新越多,也可以理解为更新的时刻。此外,每个数据页上也有一个lsn,表示最后被修改时的lsn,值越大表示越晚被修改。比如,数据页A的lsn为100,数据页B的lsn为200,checkpoint lsn为150,系统lsn为300,表示当前系统已经更新到300,小于150的数据页已经被刷到磁盘上,因此数据页A的最新数据一定在磁盘上,而数据页B则不一定,有可能还在内存中。
redo日志: 现代数据库都需要写redo日志,例如修改一条数据,首先写redo日志,然后再写数据。在写完redo日志后,就直接给客户端返回成功。这样虽然看过去多写了一次盘,但是由于把对磁盘的随机写入(写数据)转换成了顺序的写入(写redo日志),性能有很大幅度的提高。当数据库挂了之后,通过扫描redo日志,就能找出那些没有刷盘的数据页(在崩溃之前可能数据页仅仅在内存中修改了,但是还没来得及写盘),保证数据不丢。
undo日志: 数据库还提供类似撤销的功能,当你发现修改错一些数据时,可以使用rollback指令回滚之前的操作。这个功能需要undo日志来支持。此外,现代的关系型数据库为了提高并发(同一条记录,不同线程的读取不冲突,读写和写读不冲突,只有同时写才冲突),都实现了类似MVCC的机制,在InnoDB中,这个也依赖undo日志。为了实现统一的管理,与redo日志不同,undo日志在Buffer Pool中有对应的数据页,与普通的数据页一起管理,依据LRU规则也会被淘汰出内存,后续再从磁盘读取。与普通的数据页一样,对undo页的修改,也需要先写redo日志。
检查点: 英文名为checkpoint。数据库为了提高性能,数据页在内存修改后并不是每次都会刷到磁盘上。checkpoint之前的数据页保证一定落盘了,这样之前的日志就没有用了(由于InnoDB redolog日志循环使用,这时这部分日志就可以被覆盖),checkpoint之后的数据页有可能落盘,也有可能没有落盘,所以checkpoint之后的日志在崩溃恢复的时候还是需要被使用的。InnoDB会依据脏页的刷新情况,定期推进checkpoint,从而减少数据库崩溃恢复的时间。检查点的信息在第一个日志文件的头部。
崩溃恢复: 用户修改了数据,并且收到了成功的消息,然而对数据库来说,可能这个时候修改后的数据还没有落盘,如果这时候数据库挂了,重启后,数据库需要从日志中把这些修改后的数据给捞出来,重新写入磁盘,保证用户的数据不丢。这个从日志中捞数据的过程就是崩溃恢复的主要任务,也可以成为数据库前滚。当然,在崩溃恢复中还需要回滚没有提交的事务,提交没有提交成功的事务。由于回滚操作需要undo日志的支持,undo日志的完整性和可靠性需要redo日志来保证,所以崩溃恢复先做redo前滚,然后做undo回滚。
数据库崩溃恢复过程
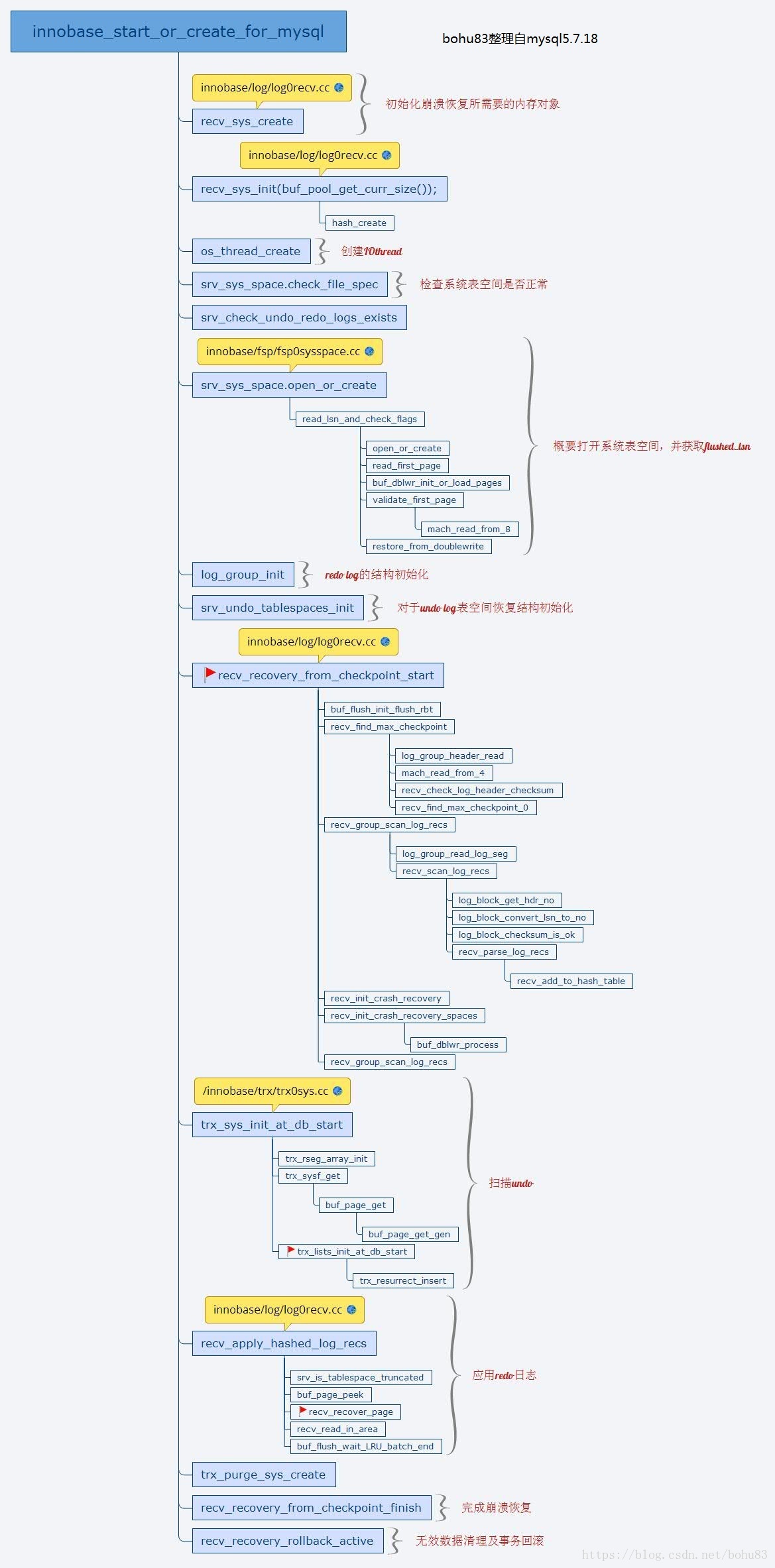
下面看一下数据库崩溃恢复过程。整个过程都在引擎初始化阶段完成(innobase_init),其中最主要的函数是innobase_start_or_create_for_mysql,innodb通过这个函数完成创建和初始化,包括崩溃恢复。首先来介绍一下数据库的前滚。
崩溃恢复相关参数解析
innodb_fast_shutdown
innodb_fast_shutdown = 0。这个表示在MySQL关闭的时候,执行slow shutdown,不但包括日志的刷盘,数据页的刷盘,还包括数据的清理(purge),ibuf的合并,buffer pool dump以及lazy table drop操作(如果表上有未完成的操作,即使执行了drop table且返回成功了,表也不一定立刻被删除)。 innodb_fast_shutdown = 1。这个是默认值,表示在MySQL关闭的时候,仅仅把日志和数据刷盘。 innodb_fast_shutdown = 2。这个表示关闭的时候,仅仅日志刷盘,其他什么都不做,就好像MySQL crash了一样。 这个参数值越大,MySQL关闭的速度越快,但是启动速度越慢,相当于把关闭时候需要做的工作挪到了崩溃恢复上。另外,如果MySQL要升级,建议使用第一种方式进行一次干净的shutdown。
innodb_force_recovery
这个参数主要用来控制InnoDB启动时候做哪些工作,数值越大,做的工作越少,启动也更加容易,但是数据不一致的风险也越大。当MySQL因为某些不可控的原因不能启动时,可以设置这个参数,从1开始逐步递增,知道MySQL启动,然后使用SELECT INTO OUTFILE把数据导出,尽最大的努力减少数据丢失。 innodb_force_recovery = 0。这个是默认的参数,启动的时候会做所有的事情,包括redo日志应用,undo日志回滚,启动后台master和purge线程,ibuf合并。检测到了数据页损坏了,如果是系统表空间的,则会crash,用户表空间的,则打错误日志。
innodb_force_recovery = 1。如果检测到数据页损坏了,不会crash也不会报错(buf_page_io_complete),启动的时候也不会校验表空间第一个数据页的正确性(fil_check_first_page),表空间无法访问也继续做崩溃恢复(fil_open_single_table_tablespace、fil_load_single_table_tablespace),ddl操作不能进行(check_if_supported_inplace_alter),同时数据库也被不能进行写入操作(row_insert_for_mysql、row_update_for_mysql等),所有的prepare事务也会被回滚(trx_resurrect_insert、trx_resurrect_update_in_prepared_state)。这个选项还是很常用的,数据页可能是因为磁盘坏了而损坏了,设置为1,能保证数据库正常启动。 innodb_force_recovery = 2。除了设置1之后的操作不会运行,后台的master和purge线程就不会启动了(srv_master_thread、srv_purge_coordinator_thread等),当你发现数据库因为这两个线程的原因而无法启动时,可以设置。
innodb_force_recovery = 3。除了设置2之后的操作不会运行,undo回滚数据库也不会进行,但是回滚段依然会被扫描,undo链表也依然会被创建(trx_sys_init_at_db_start)。srv_read_only_mode会被打开。
innodb_force_recovery = 4。除了设置3之后的操作不会运行,ibuf的操作也不会运行(ibuf_merge_or_delete_for_page),表信息统计的线程也不会运行(因为一个坏的索引页会导致数据库崩溃)(info_low、dict_stats_update等)。从这个选项开始,之后的所有选项,都会损坏数据,慎重使用。
innodb_force_recovery = 5。除了设置4之后的操作不会运行,回滚段也不会被扫描(recv_recovery_rollback_active),undo链表也不会被创建,这个主要用在undo日志被写坏的情况下。
innodb_force_recovery = 6。除了设置5之后的操作不会运行,数据库前滚操作也不会进行,包括解析和应用(recv_recovery_from_checkpoint_start_func)。
总结
InnoDB实现了一套完善的崩溃恢复机制,保证在任何状态下(包括在崩溃恢复状态下)数据库挂了,都能正常恢复,这个是与文件系统最大的差别。