





对象在内存中的内存布局
对象的内存布局
HotSpot虚拟机中,对象在内存中存储的布局可以分为三块区域:对象头(Header)、实例数据(Instance Data)和对齐填充(Padding)。
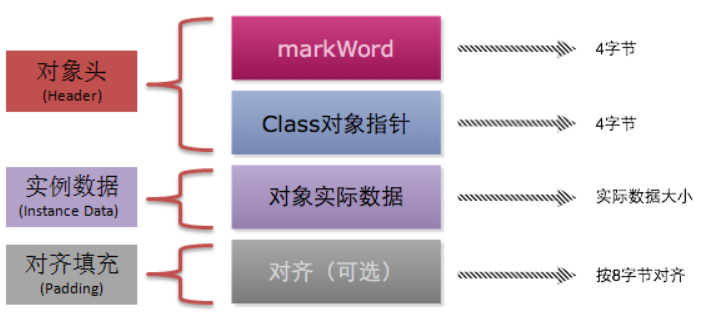
从上面的这张图里面可以看出,对象在内存中的结构主要包含以下几个部分:
- Mark Word(标记字段):对象的Mark Word部分占4个字节,其内容是一系列的标记位,比如轻量级锁的标记位,偏向锁标记位等等。
- Klass Pointer(Class对象指针):Class对象指针的大小也是4个字节,其指向的位置是对象对应的Class对象(其对应的元数据对象)的内存地址
- 对象实际数据:这里面包括了对象的所有成员变量,其大小由各个成员变量的大小决定,比如:byte和boolean是1个字节,short和char是2个字节,int和float是4个字节,long和double是8个字节,reference是4个字节
- 对齐:最后一部分是对齐填充的字节,按8个字节填充。
对象头
Mark Word(标记字段)
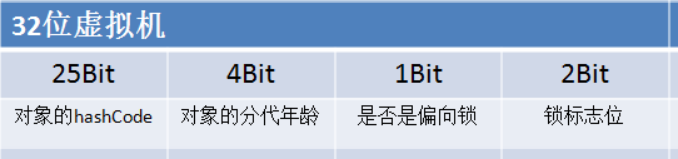
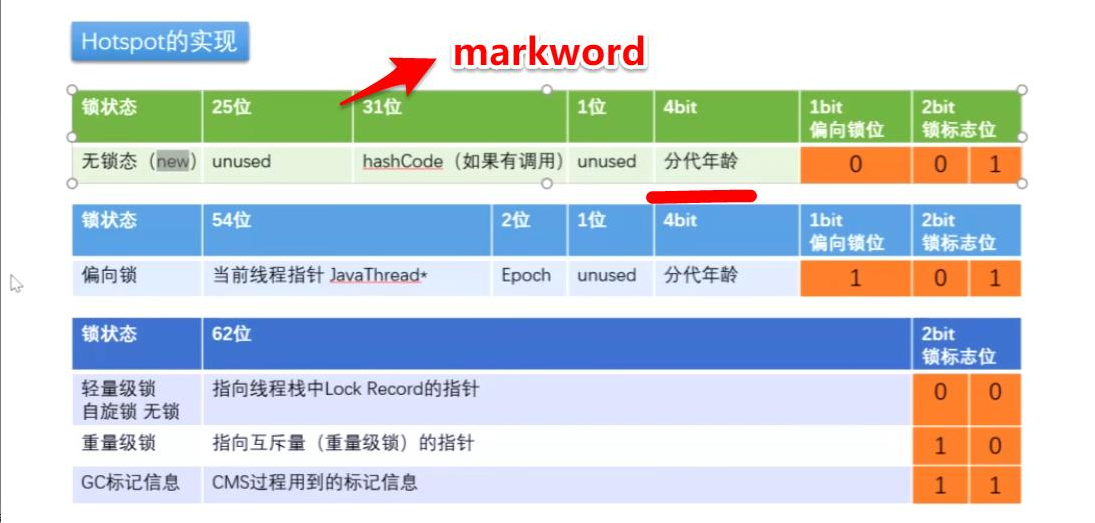
HotSpot虚拟机的对象头包括两部分信息,第一部分是“Mark Word”,用于存储对象自身的运行时数据, 如哈希码(HashCode)、GC分代年龄、锁状态标志、线程持有的锁、偏向线程ID、偏向时间戳等等,这部分数据的长度在32位和64位的虚拟机(暂 不考虑开启压缩指针的场景)中分别为32个和64个Bits,官方称它为“Mark Word”。对象需要存储的运行时数据很多,其实已经超出了32、64位Bitmap结构所能记录的限度,但是对象头信息是与对象自身定义的数据无关的额 外存储成本,考虑到虚拟机的空间效率,Mark Word被设计成一个非固定的数据结构以便在极小的空间内存储尽量多的信息,它会根据对象的状态复用自己的存储空间。例如在32位的HotSpot虚拟机 中对象未被锁定的状态下,Mark Word的32个Bits空间中的25Bits用于存储对象哈希码(HashCode),4Bits用于存储对象分代年龄,2Bits用于存储锁标志 位,1Bit固定为0,在其他状态(轻量级锁定、重量级锁定、GC标记、可偏向)下对象的存储内容如下表所示。
但是如果对象是数组类型,则需要三个机器码,因为JVM虚拟机可以通过Java对象的元数据信息确定Java对象的大小,但是无法从数组的元数据来确认数组的大小,所以用一块来记录数组长度。
对象头信息是与对象自身定义的数据无关的额外存储成本,但是考虑到虚拟机的空间效率,Mark Word被设计成一个非固定的数据结构以便在极小的空间内存存储尽量多的数据,它会根据对象的状态复用自己的存储空间,也就是说,Mark Word会随着程序的运行发生变化,变化状态如下(32位虚拟机):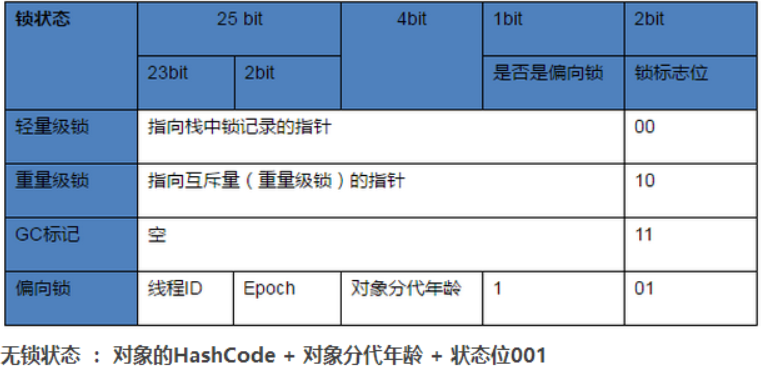
HotSpot虚拟机对象头Mark Word:
| 存储内容 | 标志位 | 状态 |
|---|---|---|
| 对象哈希码、对象分代年龄 | 01 | 未锁定 |
| 指向锁记录的指针 | 00 | 轻量级锁定 |
| 指向重量级锁的指针 | 10 | 膨胀(重量级锁定) |
| 空,不需要记录信息 | 11 | GC标记 |
| 偏向线程ID、偏向时间戳、对象分代年龄 | 01 | 可偏向 |
注意偏向锁、轻量级锁、重量级锁等都是jdk 1.6以后引入的。
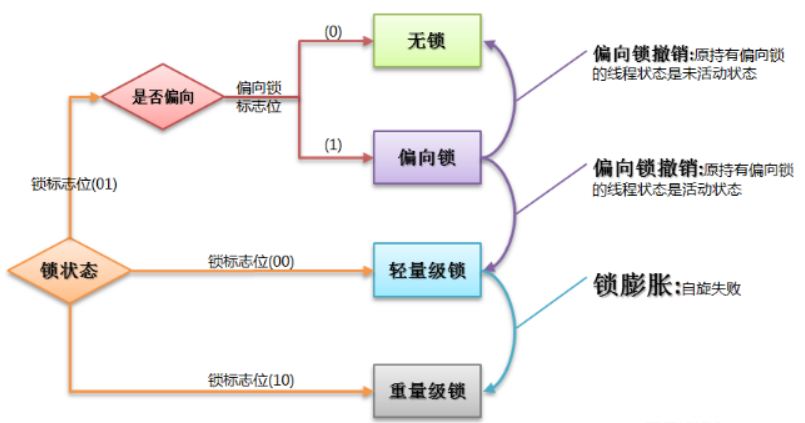
其中轻量级锁和偏向锁是Java 6 对 synchronized 锁进行优化后新增加的,稍后我们会简要分析。这里我们主要分析一下重量级锁也就是通常说synchronized的对象锁,锁标识位为10,其中指针指向的是monitor对象(也称为管程或监视器锁)的起始地址。每个对象都存在着一个 monitor 与之关联,对象与其 monitor 之间的关系有存在多种实现方式,如monitor可以与对象一起创建销毁或当线程试图获取对象锁时自动生成,但当一个 monitor 被某个线程持有后,它便处于锁定状态。在Java虚拟机(HotSpot)中,monitor是由ObjectMonitor实现的,其主要数据结构如下(位于HotSpot虚拟机源码ObjectMonitor.hpp文件,C++实现的)
1 | ObjectMonitor() { |
ObjectMonitor中有两个队列,_WaitSet 和 _EntryList,用来保存ObjectWaiter对象列表( 每个等待锁的线程都会被封装成ObjectWaiter对象),_owner指向持有ObjectMonitor对象的线程,当多个线程同时访问一段同步代码时,首先会进入 _EntryList 集合,当线程获取到对象的monitor 后进入 _Owner 区域并把monitor中的owner变量设置为当前线程同时monitor中的计数器count加1,若线程调用 wait() 方法,将释放当前持有的monitor,owner变量恢复为null,count自减1,同时该线程进入 WaitSe t集合中等待被唤醒。若当前线程执行完毕也将释放monitor(锁)并复位变量的值,以便其他线程进入获取monitor(锁)。如下图所示:
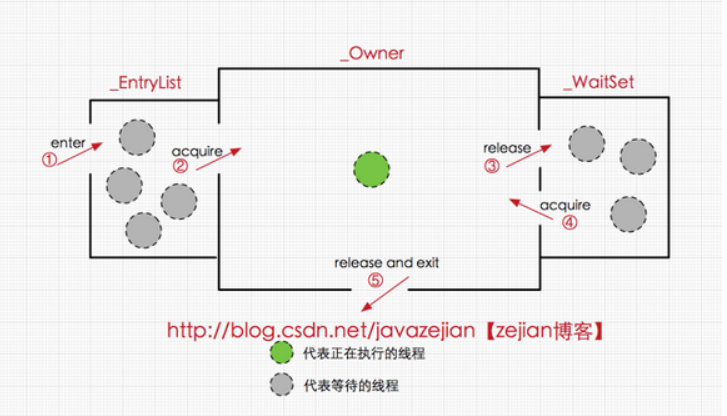
由此看来,monitor对象存在于每个Java对象的对象头中(存储的指针的指向),synchronized锁便是通过这种方式获取锁的,也是为什么Java中任意对象可以作为锁的原因,同时也是notify/notifyAll/wait等方法存在于顶级对象Object中的原因(关于这点稍后还会进行分析),ok~,有了上述知识基础后,下面我们将进一步分析synchronized在字节码层面的具体语义实现。
对象头的另外一部分是类型指针,即是对象指向它的类的元数据的指针,虚拟机通过这个指针来确定这个对象是哪个类的实例。并不是所有的虚拟机实现都必须在对象数据上保留类型指针,换句话说查找对象的元数据信息并不一定要经过对象本身。另外,如果对象是一个Java数组,那在对象头中还必须有一块用于记录数组长度的数据,因为虚拟机可以通过普通Java对象的元数据信息确定Java对象的大小,但是从数组的元数据中无法确定数组的大小。
以下是HotSpot虚拟机markOop.cpp中的C++代码(注释)片段,它描述了32bits下MarkWord的存储状态:
1 | // Bit-format of an object header (most significant first, big endian layout below): |
实例数据(Instance Data)
接下来实例数据部分是对象真正存储的有效信息,也既是我们在程序代码里面所定义的各种类型的字段内容,无论是从父类继承下来的,还是在子类中定义的都需要记录下来。 这部分的存储顺序会受到虚拟机分配策略参数(FieldsAllocationStyle)和字段在Java源码中定义顺序的影响。HotSpot虚拟机 默认的分配策略为longs/doubles、ints、shorts/chars、bytes/booleans、oops(Ordinary Object Pointers),从分配策略中可以看出,相同宽度的字段总是被分配到一起。在满足这个前提条件的情况下,在父类中定义的变量会出现在子类之前。如果 CompactFields参数值为true(默认为true),那子类之中较窄的变量也可能会插入到父类变量的空隙之中。
对齐填充(Padding)
第三部分对齐填充并不是必然存在的,也没有特别的含义,它仅仅起着占位符的作用。由于HotSpot VM的自动内存管理系统要求对象起始地址必须是8字节的整数倍,换句话说就是对象的大小必须是8字节的整数倍。对象头正好是8字节的倍数(1倍或者2倍),因此当对象实例数据部分没有对齐的话,就需要通过对齐填充来补全。
对象的创建过程
见本站Java对象创建的过程
对象的访问定位
Java是通过虚拟机栈中的局部变量表中的reference数据来操作Java堆上的具体对象。但reference只是虚拟机规范中规定指向一个对象的引用,它并没有定义这个引用通过何种方式去定位、访问堆中的对象的具体位置,所以对象访问方法也取决于虚拟机的实现而定的。目前主流的访问方式有使用句柄和直接指针两种。
句柄访问
如果使用句柄访问,Java堆中将会划分出一块儿内存作为句柄池,reference中存储的就是对象的句柄地址,而句柄中包含了对象实例数据和对象类型数据的具体地址信息。实际上是采用了句柄池这样一个中间介质进行了两次指针定位,有效的避免了对象的移动或改变直接导致reference本身发生改变。句柄访问方式如下图所示:
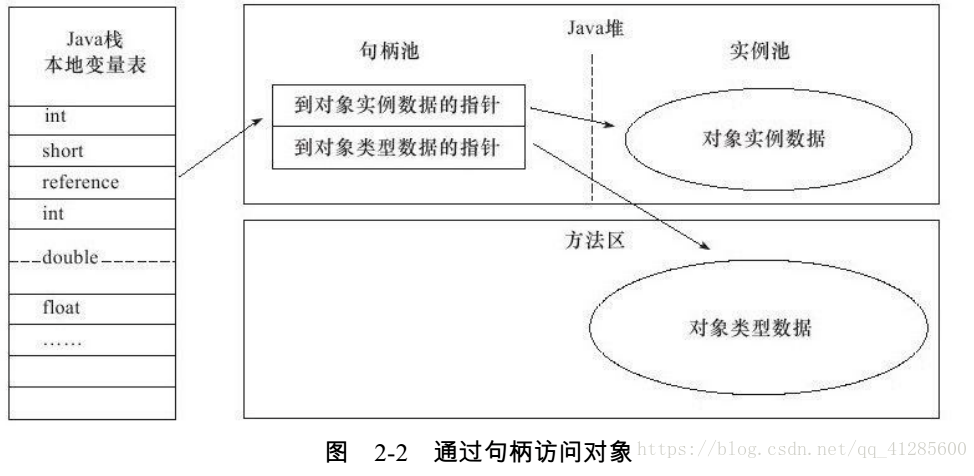
使用句柄访问最大的好处就是reference中存储的是稳定的句柄地址,在对象回收过程中或者其它对象需要移动的时,只会改变句柄中的实例数据的指针,而reference本身不需要做任何修改。
直接指针访问
如果使用直接指针访问,那么Java堆对象的布局必须考虑如何放置访问类型的数据的相关信息,而reference中存储的直接就是对象地址,而不再是句柄地址信息,相当于在reference与对象地址信息直接少了句柄池这样一个中间地址,reference中直接存储的就是对象地址。
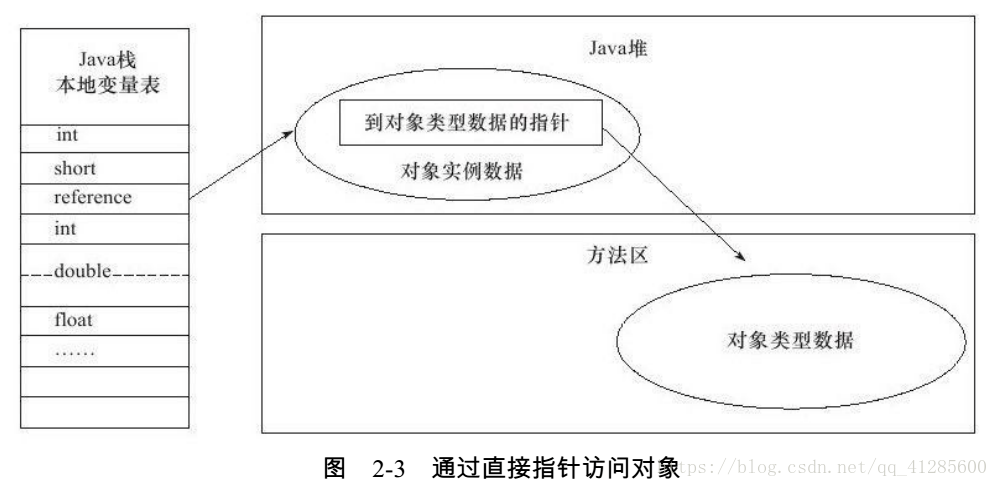
这种定位方式也就导致了在对象被移动时,reference本身必须发生改变。但是我们都知道,使用句柄访问方式时,相当于进行了两次指针定位,而直接指针访问方式恰好节省了这一次指针定位的时间开销,由于对象的访问在Java中非常的频繁,时间开销的减少也是一种可观的执行成本。例如,常见的HotSpot虚拟机就使用的是直接指针访问方式。
示例
在Hotspot JVM中,32位机器下,Integer对象的大小是int的几倍?
我们都知道在Java语言规范已经规定了int的大小是4个字节,那么Integer对象的大小是多少呢?要知道一个对象的大小,那么必须需要知道对象在虚拟机中的结构是怎样的,根据上面的图,那么我们可以得出Integer的对象的结构如下:
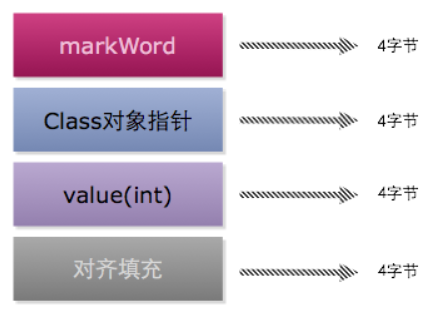
Integer只有一个int类型的成员变量value,所以其对象实际数据部分的大小是4个字节,然后再在后面填充4个字节达到8字节的对齐,所以可以得出Integer对象的大小是16个字节。
因此,我们可以得出Integer对象的大小是原生的int类型的4倍。
关于对象的内存结构,需要注意数组的内存结构和普通对象的内存结构稍微不同,因为数据有一个长度length字段,所以在对象头后面还多了一个int类型的length字段,占4个字节,接下来才是数组中的数据,如下图:

Object o = new Object()在内存中占了多少字节?
想要知道 Object o = new Object();在内存中占用了多少字节,可以使用如下方法直观的看到。
- maven中添加依赖
1
2
3
4
5<dependency>
<groupId>org.openjdk.jol</groupId>
<artifactId>jol-core</artifactId>
<version>0.9</version>
</dependency> - 写一个测试类
1
2
3
4
5
6public class ObjectLayOutTest {
public static void main(String[] args) {
Object o = new Object();
System.out.println(ClassLayout.parseInstance(o).toPrintable());
}
} - 结果

- 可以直观的看到 new Object()在内存中占用16个字节。
为什么是16个字节呢,就需要了解对象在内存中的存储布局。
- MarkWord:对象头,8字节。包括了对象的hashCode、对象的分代年龄、锁标志位等。结构如下图所示:
- classPointer:对象指向它的类元素的指针。在不开启对象指针压缩的情况下是8字节。压缩后变为4字节,默认压缩。
1 | 通过命令:java -XX:+PrintCommandLineFlags -version 查看classPointer是否开启压缩 |
- padding :用于对象在内存中占用的字节数不能被8整除的情况下,进行补充。
因此,Object o = new Object()在内存中占的字节数计算如下:
markword 8字节,因为java默认使用了calssPointer压缩,classpointer 4字节,padding 4字节 因此是16字节。
如果没开启classpointer默认压缩,markword 8字节,classpointer 8字节,padding 0字节 也是16字节。