





如何保证缓存和数据库数据的一致性?
如何保证缓存和数据库数据的一致性?
当我们对数据进行修改的时候,到底是先删缓存,还是先写数据库?
1、如果先删缓存,再写数据库: 在高并发场景下,当第一个线程删除了缓存,还没有来得及写数据库,第二个线程来读取数据,会发现缓存中的数据为空,那就会去读数据库中的数据(旧值,脏数据),读完之后,把读到的结果写入缓存(此时,第一个线程已经将新的值写到缓存里面了),这样缓存中的值就会被覆盖为修改前的脏数据。
总结: 在这种方式下,通常要求写操作不会太频繁。
解决方案:
先操作缓存,但是不删除缓存。将缓存修改为一个特殊值(-999)。客户端读缓存时,发现是默认值,就休眠一小会,再去查一次Redis。
- 问题: 1. 特殊值对业务有侵入。2. 休眠时间, 可能会多次重复,对性能有影响。
延时双删:先删除缓存,然后再写数据库,休眠一小会,再次删除缓存。
- 问题: 1. 如果数据写操作很频繁, 同样还是会有脏数据的问题。
2、先写数据库,再删缓存: 如果数据库写完了之后, 缓存删除失败,数据就会不一致。
总结: 始终只能保证一定时间内的最终一致性。
解决方案:
- 给缓存设置一个过期时间。
- 问题: 过期时间内,缓存数据不会更新。
- 引入MQ,保证原子操作。
解决方案: 将热点数据缓存设置为永不过期,但是在value当中写入一个逻辑上的过期时间,另外起一个后台线程,扫描这些key,对于已逻辑上过期的缓存,进行删除。
不是严格要求缓存+数据库必须一致性
一般来说,就是如果你的系统不是严格要求缓存+数据库必须一致性的话,缓存可以稍微的跟数据库偶尔有不一致的情况,最好不要做这个方案,读请求和写请求串行化,串到一个内存队列里去,这样就可以保证一定不会出现不一致的情况
串行化之后,就会导致系统的吞吐量会大幅度的降低,用比正常情况下多几倍的机器去支撑线上的一个请求。
最初级的缓存不一致问题及解决方案(不一致问题)
问题:先更新数据库,再删除缓存。如果删除缓存失败了,那么会导致数据库中是新数据,缓存中是旧数据,数据就出现了不一致。
因为读取数据是先读缓存的,发现缓存中有数据,就直接返回了旧数据。
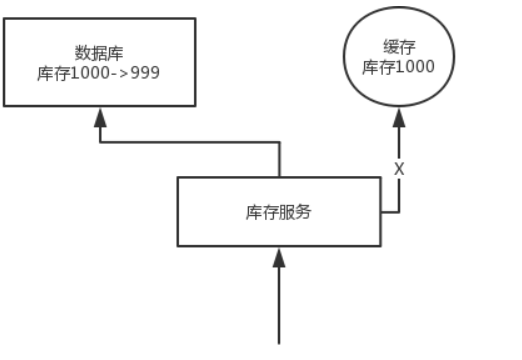
解决思路: 先删除缓存,再更新数据库。如果数据库更新失败了,那么数据库中是旧数据,缓存中是空的,那么数据不会不一致。因为读的时候缓存没有,所以去读了数据库中的旧数据,然后更新到缓存中。
比较复杂的数据不一致问题分析(不一致问题)
数据发生了变更,先删除了缓存,然后要去修改数据库,此时还没修改。一个请求过来,去读缓存,发现缓存空了,去查询数据库,查到了修改前的旧数据,放到了缓存中。随后数据变更的程序完成了数据库的修改。完了,数据库和缓存中的数据不一样了…
严格要求缓存+数据库必须一致性
将不一致分为三种情况:
数据库有数据,缓存没有数据;
数据库有数据,缓存也有数据,数据不相等;
数据库没有数据,缓存有数据。
在讨论这三种情况之前,先说明一下使用缓存的策略,叫做 Cache Aside Pattern(旁路模式)。简而言之就是
1. 首先尝试从缓存读取,读到数据则直接返回;如果读不到,就读数据库,并将数据会写到缓存,并返回。
2. 需要更新数据时,先更新数据库,然后把缓存里对应的数据失效掉(删掉)。
第一种数据库有数据,缓存没有数据: 在读数据的时候,会自动把数据库的数据写到缓存,因此不一致自动消除.
第二种数据库有数据,缓存也有数据,数据不相等: 数据最终变成了不相等,但他们之前在某一个时间点一定是相等的(不管你使用懒加载还是预加载的方式,在缓存加载的那一刻,它一定和数据库一致)。这种不一致,一定是由于你更新数据所引发的。前面我们讲了更新数据的策略,先更新数据库,然后删除缓存。因此,不一致的原因,一定是数据库更新了,但是删除缓存失败了。
第三种数据库没有数据,缓存有数据, 情况和第二种类似,你把数据库的数据删了,但是删除缓存的时候失败了。
因此,最终的结论是,需要解决的不一致,产生的原因是更新数据库成功,但是删除缓存失败。
解决方案大概有以下几种:
对删除缓存进行重试,数据的一致性要求越高,我越是重试得快。
定期全量更新,简单地说,就是我定期把缓存全部清掉,然后再全量加载。
给所有的缓存一个失效期。
第三种方案可以说是一个大杀器,任何不一致,都可以靠失效期解决,失效期越短,数据一致性越高。但是失效期越短,查数据库就会越频繁。因此失效期应该根据业务来定。
并发不高的情况:
读: 读redis->没有,读mysql->把mysql数据写回redis,有的话直接从redis中取;
写: 写mysql->成功,再写redis;
并发高的情况:
读: 读redis->没有,读mysql->把mysql数据写回redis,有的话直接从redis中取;
写:异步话,先写入redis的缓存,就直接返回;定期或特定动作将数据保存到mysql,可以做到多次更新,一次保存;
分布式锁解决缓存和数据库一致性问题
在平时开发中,利用分布式锁可能算是比较常见的解决方案了。利用分布式锁把缓存操作和数据库操作封装为逻辑上的一个操作可以保证数据的一致性,具体流程为:
- 每个想要操作缓存和数据库的线程都必须先申请分布式锁。
- 如果成功获得锁,则进行数据库和缓存操作,操作完毕释放锁。
- 如果没有获得锁,根据不同业务可以选择阻塞等待或者轮训,或者直接返回的策略。
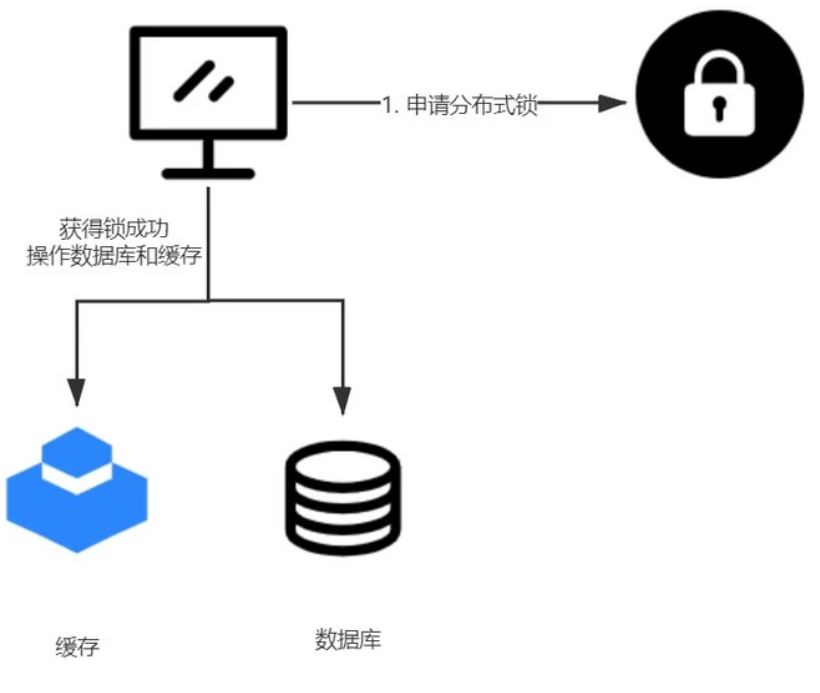
利用分布式锁是解决分布式事务的一种方案,但是在一定程度上会降低系统的性能,而且分布式锁的设计要考虑到down机和死锁的意外情况,而最常见的分布式锁就是利用redis,但是也会有不少坑。
为什么是删除缓存,而不是更新缓存?
原因很简单,很多时候,在复杂点的缓存场景,缓存不单单是数据库中直接取出来的值。
比如可能更新了某个表的一个字段,然后其对应的缓存,是需要查询另外两个表的数据并进行运算,才能计算出缓存最新的值的。
另外更新缓存的代价有时候是很高的。是不是说,每次修改数据库的时候,都一定要将其对应的缓存更新一份?也许有的场景是这样,但是对于比较复杂的缓存数据计算的场景,就不是这样了。如果你频繁修改一个缓存涉及的多个表,缓存也频繁更新。但是问题在于,这个缓存到底会不会被频繁访问到?
举个栗子,一个缓存涉及的表的字段,在 1 分钟内就修改了 20 次,或者是 100 次,那么缓存更新 20 次、100 次;但是这个缓存在 1 分钟内只被读取了 1 次,有大量的冷数据。实际上,如果你只是删除缓存的话,那么在 1 分钟内,这个缓存不过就重新计算一次而已,开销大幅度降低。用到缓存才去算缓存。
其实删除缓存,而不是更新缓存,就是一个 lazy 计算的思想,不要每次都重新做复杂的计算,不管它会不会用到,而是让它到需要被使用的时候再重新计算。像 mybatis,hibernate,都有懒加载思想。查询一个部门,部门带了一个员工的 list,没有必要说每次查询部门,都里面的 1000 个员工的数据也同时查出来啊。80% 的情况,查这个部门,就只是要访问这个部门的信息就可以了。先查部门,同时要访问里面的员工,那么这个时候只有在你要访问里面的员工的时候,才会去数据库里面查询 1000 个员工。