





一文搞懂 Redis 高性能之 IO 多路复用
本文从 IO 并发性能提升来整体思考,来逐步剖析 IO 多路复用的原理。
一、如何快速理解 IO 多路复用?
多进程
多线程
基于单进程的 IO 多路复用(select/poll/epoll)
1、多进程
对于并发情况,假如一个进程不行,那搞多个进程不就可以同时处理多个客户端连接了么?
多进程这种方式的确可以解决了服务器在同一时间能处理多个客户端连接请求的问题,但是仍存在一些缺点:
fork()等系统调用会使得进程上下文进行切换,效率较低
进程创建的数量随着连接请求的增加而增加。比如 10w 个请求,就要 fork 10w 个进程,开销太大
进程与进程之间的地址空间是私有、独立的,使得进程之间的数据共享变得困难
2、多线程
线程是运行在进程上下文的逻辑流,一个进程可以包含多个线程,多个线程运行在同一进程上下文中,因此可共享这个进程地址空间的所有内容,解决了进程与进程之间通信难的问题。
同时,由于一个线程的上下文要比一个进程的上下文小得多,所以线程的上下文切换,要比进程的上下文切换效率高得多。
3、IO 多路复用
简单理解就是:一个服务端进程可以同时处理多个套接字描述符。
多路:多个客户端连接(连接就是套接字描述符)
复用:使用单进程就能够实现同时处理多个客户端的连接
以上是通过增加进程和线程的数量来并发处理多个套接字,免不了上下文切换的开销,而 IO 多路复用只需要一个进程就能够处理多个套接字,从而解决了上下文切换的问题。
其发展可以分 select->poll→epoll 三个阶段来描述。
二、如何简单理解 select/poll/epoll 呢?
按照以往惯例,还是联系一下我们日常中的现实场景,这样更助于大家理解。
举栗说明:
领导分配员工开发任务,有些员工还没完成。如果领导要每个员工的工作都要验收 check,那在未完成的员工那里,只能阻塞等待,等待他完成之后,再去 check 下一位员工的任务,造成性能问题。
那如何解决这个问题呢?
1、select
举栗说明:
领导找个 Team Leader(后文简称 TL),负责代自己 check 每位员工的开发任务。
TL 的做法是:遍历问各个员工“完成了么?”,完成的待 CR check 无误后合并到 Git 分支,对于其他未完成的,休息一会儿后再去遍历….
这样存在什么问题呢?
这个 TL 存在能力短板问题,最多只能管理 1024 个员工
很多员工的任务没有完成,而且短时间内也完不成的话,TL 还是会不停的去遍历问询,影响效率。
select 函数:
1 | int select(int maxfdp1,fd_set *readset,fd_set *writeset,fd_set *exceptset,const struct timeval *timeout); |
select 函数监视的文件描述符分 3 类,分别是 writefds、readfds、和 exceptfds。调用后 select 函数会阻塞,直到有描述符就绪(有数据可读、可写、或者有 except),或者超时(timeout 指定等待时间,如果立即返回设为 null 即可),函数返回。当 select 函数返回后,可以通过遍历 fdset,来找到就绪的描述符。
select 具有良好的跨平台支持,其缺点在于单个进程能够监视的文件描述符的数量存在最大限制,在 Linux 上一般为 1024。
2、poll
举栗说明:
换一个能力更强的 New Team Leader(后文简称 NTL),可以管理更多的员工,这个 NTL 可以理解为 poll。
poll 函数:
1 | intpoll(structpollfd*fds, nfds_t nfds,int timeout); |
poll 改变了文件描述符集合的描述方式,使用了 pollfd 结构而不是 select 的 fd_set 结构,使得 poll 支持的文件描述符集合限制远大于 select 的 1024。
3、epoll
举栗说明:
在上一步 poll 方式的 NTL 基础上,改进一下 NTL 的办事方法:遍历一次所有员工,如果任务没有完成,告诉员工待完成之后,其应该做 xx 操作(制定一些列的流程规范)。这样 NTL 只需要定期 check 指定的关键节点就好了。这就是 epoll。
Linux 中提供的 epoll 相关函数如下:
1 | intepoll_create(int size); |
epoll 是 Linux 内核为处理大批量文件描述符而作了改进的 poll,是 Linux 下多路复用 IO 接口 select/poll 的增强版本,它能显著提高程序在大量并发连接中只有少量活跃的情况下的系统 CPU 利用率。
4、小结
select 就是轮询,在 Linux 上限制个数一般为 1024 个
poll 解决了 select 的个数限制,但是依然是轮询
epoll 解决了个数的限制,同时解决了轮询的方式
三、IO 多路复用在 Redis 中的应用
Redis 服务器是一个事件驱动程序, 服务器处理的事件分为时间事件和文件事件两类。
文件事件:Redis 主进程中,主要处理客户端的连接请求与相应。
时间事件:fork 出的子进程中,处理如 AOF 持久化任务等。
由于 Redis 的文件事件是单进程,单线程模型,但是确保持着优秀的吞吐量,IO 多路复用起到了主要作用。
文件事件是对套接字操作的抽象,每当一个套接字准备好执行连接应答、写入、读取、关闭等操作时,就会产生一个文件事件。因为一个服务器通常会连接多个套接字,所以多个文件事件有可能会并发地出现。
IO 多路复用程序负责监听多个套接字并向文件事件分派器传送那些产生了事件的套接字。文件事件分派器接收 IO 多路复用程序传来的套接字,并根据套接字产生的事件的类型,调用相应的事件处理器。示例如图所示:
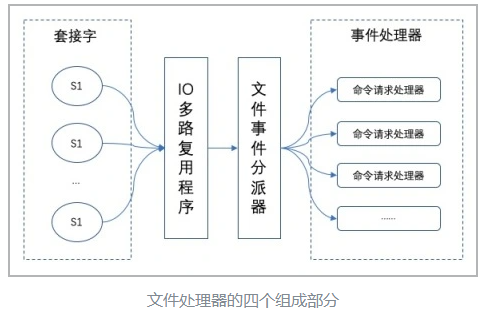
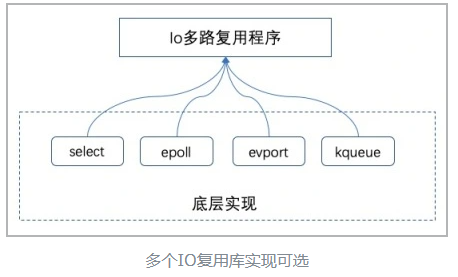
Redis 的 IO 多路复用程序的所有功能都是通过包装常见的 select、poll、evport 和 kqueue 这些 IO 多路复用函数库来实现的,每个 IO 多路复用函数库在 Redis 源码中都有对应的一个单独的文件。
Redis 为每个 IO 多路复用函数库都实现了相同的 API,所以 IO 多路复用程序的底层实现是可以互换的。如图:
Redis 把所有连接与读写事件、还有我们没提到的时间事件一起集中管理,并对底层 IO 多路复用机制进行了封装,最终实现了单进程能够处理多个连接以及读写事件。这就是 IO 多路复用在 redis 中的应用。
四、总结
Redis 6.0 之后的版本开始选择性使用多线程模型。
Redis 选择使用单线程模型处理客户端的请求主要还是因为 CPU 不是 Redis 服务器的瓶颈,使用多线程模型带来的性能提升并不能抵消它带来的开发成本和维护成本,系统的性能瓶颈也主要在网络 I/O 操作上;
而 Redis 引入多线程操作也是出于性能上的考虑,对于一些大键值对的删除操作,通过多线程非阻塞地释放内存空间也能减少对 Redis 主线程阻塞的时间,提高执行的效率。
凡事不能有绝对,寻找到适中的平衡点最重要!