





Redis 五大数据类型
Redis 五大数据类型详述…
Redis-key
String(字符串)
简介
Strings 数据结构是简单的key-value类型,value其实不仅是String,也可以是数字.
常用命令
set,get,decr,incr,mget 等。
String是最常用的一种数据类型,普通的key/ value 存储都可以归为此类.即可以完全实现目前 Memcached 的功能,并且效率更高。还可以享受Redis的定时持久化,操作日志及 Replication等功能。除了提供与 Memcached 一样的get、set、incr、decr 等操作外,Redis还提供了下面一些操作:
- set: 设置指定 key 的值
- get: 获取指定 key 的值。
- getrange: 获取值的部分
- getset: 将给定 key 的值设为 value ,并返回 key 的旧值(old value)。
- getbit: 对 key 所储存的字符串值,获取指定偏移量上的位(bit)。
- setbit: 对 key 所储存的字符串值,设置或清除指定偏移量上的位(bit)。
- mget: 获取多个key
- setnx: key不存在时才设置value
- setex: 将值value关联到key,并将key的过期时间设为seconds
- psetex: 将值value关联到key,并将key的过期时间设为毫秒
- setrange: 用 value 参数覆写给定 key 所储存的字符串值,从偏移量 offset 开始。
- strlen: 返回 key 所储存的字符串值的长度。
- mset: 设置多对key/value的值
- msetnx: 同时设置一个或多个 key-value 对,当且仅当所有给定 key 都不存在。
- incr: 值增加1
- incrby: 将 key 所储存的值加上给定的增量值(increment) 。
- decr: 值减1
- decrby: key 所储存的值减去给定的减量值(decrement) 。
- append: 添加到尾部
- del: 该命令用于在 key 存在时删除 key。
- dump: 序列化给定 key ,并返回被序列化的值。
- exists: 检查给定 key 是否存在。
- expire: 为给定 key 设置过期时间,以秒计。
- expireat: EXPIREAT 的作用和 EXPIRE 类似,都用于为 key 设置过期时间。 不同在于 EXPIREAT 命令接受的时间参数是 UNIX 时间戳(unix timestamp)。
- pexpire: 设置 key 的过期时间以毫秒计。
- pexpireat: 设置 key 过期时间的时间戳(unix timestamp) 以毫秒计
- keys: 查找所有符合给定模式( pattern)的 key 。
- move: 将当前数据库的 key 移动到给定的数据库 db 当中。
- persist: 移除 key 的过期时间,key 将持久保持。
- pttl: 以毫秒为单位返回 key 的剩余的过期时间。
- ttl: 以秒为单位,返回给定 key 的剩余生存时间(TTL, time to live)。
- randomkey: 从当前数据库中随机返回一个 key 。
- rename: 修改 key 的名称
- renamenx: 仅当 newkey 不存在时,将 key 改名为 newkey 。
- type: 查询数据类型
应用场景
- 商品编号、订单号采用INCR命令生成
- 是否喜欢的文章
实现方式
String在redis内部存储默认就是一个字符串,被redisObject所引用,当遇到incr,decr等操作时会转成数值型进行计算,此时redisObject的encoding字段为int。
代码示例
1 | 127.0.0.1:6379> set key1 v1 |
String类似的使用场景:value除了是字符串还可以是数字
- 计数器
- 统计多单位的数量
- 粉丝数
- 对象缓存存储!
List
基本数据类型,列表
所有的list命令都是以l开头
常用命令
lpush,rpush,lpop,rpop,lrange等。
- blpop: 移出并获取列表的第一个元素, 如果列表没有元素会阻塞列表直到等待超时或发现可弹出元素为止。
- brpop: 移出并获取列表的最后一个元素, 如果列表没有元素会阻塞列表直到等待超时或发现可弹出元素为止。
- brpoplpush: 从列表中弹出一个值,将弹出的元素插入到另外一个列表中并返回它; 如果列表没有元素会阻塞列表直到等待超时或发现可弹出元素为止。
- lindex: 通过索引获取列表中的元素
- linsert: 在列表的元素前或者后插入元素
- llen: 获取列表长度
- lpop: 移出并获取列表的第一个元素
- lpush: 将一个或多个值插入到列表头部
- lpushx: 将一个值插入到已存在的列表头部
- lrange: 获取列表指定范围内的元素
- lrem: 移除列表元素
- lset: 通过索引设置列表元素的值
- ltrim: 对一个列表进行修剪(trim),就是说,让列表只保留指定区间内的元素,不在指定区间之内的元素都将被删除。
- rpop: 移除列表的最后一个元素,返回值为移除的元素。
- rpoplpush: 移除列表的最后一个元素,并将该元素添加到另一个列表并返回
- rpush: 在列表中添加一个或多个值
- rpushx: 为已存在的列表添加值
应用场景
Redis list 的应用场景非常多,也是 Redis 最重要的数据结构之一,比如 twitter 的关注列表,粉丝列表等都可以用 Redis 的 list 结构来实现,还可以做消息队,列息队列不仅被用于系统内部组件之间的通信,同时也被用于系统跟其它服务之间的交互。消息队列的使用可以增加系统的可扩展性、灵活性和用户体验。非基于消息队列的系统,其运行速度取决于系统中最慢的组件的速度(注:木桶效应)。而基于消息队列可以将系统中各组件解除耦合,这样系统就不再受最慢组件的束缚,各组件可以异步运行从而得以更快的速度完成各自的工作。此外,当服务器处在高并发操作的时候,比如频繁地写入日志文件。可以利用消息队列实现异步处理。从而实现高性能的并发操作。
微信文章订阅公众号
- 大V作者李永乐老师和ICSDN发布了文章分别是11和22
- 阳哥关注了他们两个,只要他们发布了新文章,就会安装进我的List
- lpush likearticle:阳哥id1122
- 查看阳哥自己的号订阅的全部文章,类似分页,下面0~10就是一次显示10条
- lrange likearticle:阳哥id 0 10
实现方式
Redis list 的实现为一个双向链表,即可以支持反向查找和遍历,更方便操作,不过带来了部分额外的内存开销,Redis 内部的很多实现,包括发送缓冲队列等也都是用的这个数据结构。
代码示例
1 | ########################################## |
小结
- 实际上是一个链表,before Node after, left right都可以插入值
- 如果key不存在,创建新的链表
- 如果key存在,新增内容
- 如果移除了所有值,空链表,也代表不存在!
- 在两边插入或者改动值,效率最高!中间元素,相对来说效率会低一点~
消息排队! 消息队列 (lpush rpop),栈(lpush lpop)
Set(集合)
常用命令
sadd,spop,smembers,sunion 等。
- sadd:
- scard:
- sdiff:
- sdiffstore:
- sinsert:
- sinsertstore:
- sismember:
- smembers:
- smove:
- spop:
- srandomember:
- srem:
- sunion:
- sunionstore:
- sscan:
- sunionstore:
- sscan:
应用场景
Redis set 对外提供的功能与 list 类似是一个列表的功能,特殊之处在于 set 是可以自动排重的,当你需要存储一个列表数据,又不希望出现重复数据时,set 是一个很好的选择,并且 set 提供了判断某个成员是否在一个 set 集合内的重要接口,这个也是 list 所不能提供的。
微信抽奖小程序
- 用户ID,立即参与按钮
- SADD key 用户ID
- 显示已经有多少人参与了、上图23208人参加
- SCARD key
- 抽奖(从set中任意选取N个中奖人)
- SRANDMEMBER key 2(随机抽奖2个人,元素不删除)
- SPOP key 3(随机抽奖3个人,元素会删除)
微信朋友圈点赞
- 新增点赞
- sadd pub:msglD 点赞用户ID1 点赞用户ID2
- 取消点赞
- srem pub:msglD 点赞用户ID
- 展现所有点赞过的用户
- SMEMBERS pub:msglD
- 点赞用户数统计,就是常见的点赞红色数字
- scard pub:msgID
- 判断某个朋友是否对楼主点赞过
- SISMEMBER pub:msglD用户ID
微博好友关注社交关系
- 共同关注:我去到局座张召忠的微博,马上获得我和局座共同关注的人
- sadd s1 1 2 3 4 5
- sadd s2 3 4 5 6 7
- SINTER s1 s2
- 我关注的人也关注他(大家爱好相同)
QQ内推可能认识的人
- sadd s1 1 2 3 4 5
- sadd s2 3 4 5 6 7
- SINTER s1 s2
- SDIFF s1 s2
- SDIFF s2 s1
实现方式
set 的内部实现是一个 value 永远为 null 的 HashMap,实际就是通过计算 hash 的方式来快速排重的,这也是 set 能提供判断一个成员是否在集合内的原因。
代码示例
1 | ########################################## |
微博,A用户将所有关注的人放在一个set集合中! 将他的粉丝也放在一个集合中!
共同关注,共同爱好,二度好友,推荐好友!(六度分割理论)
Hash(哈希)
Map 集合,key-map!
常用命令
hget,hset,hgetall ,hincrby,hlen等。
- hdel: 删除一个或多个哈希表字段
- hexists: 查看哈希表 key 中,指定的字段是否存在。
- hset: 将哈希表 key 中的字段 field 的值设为 value 。
- hsetnx: 只有在字段 field 不存在时,设置哈希表字段的值。
- hget: 获取存储在哈希表中指定字段的值。
- hgetall: 获取在哈希表中指定 key 的所有字段和值
- hincrby: 为哈希表 key 中的指定字段的整数值加上增量 increment 。
- hkeys: 获取所有哈希表中的字段
- hlen: 获取哈希表中字段的数量
- hmget: 获取所有给定字段的值
- hmset: 同时将多个 field-value (域-值)对设置到哈希表 key 中。
- hvals: 获取哈希表中所有值。
- hscan: 迭代哈希表中的键值对。
应用场景
购物车早期,当前小中厂可用
- 新增商品 hset shopcar:uid1024 334488 1
- 新增商品 hset shopcar:uid1024 334477 1
- 增加商品数量 hincrby shopcar:uid1024 334477 1
- 商品总数 hlen shopcar:uid1024
- 全部选择 hgetall shopcar:uid1024
在Memcached中,我们经常将一些结构化的信息打包成HashMap,在客户端序列化后存储为一个字符串的值,比如用户的昵称、年龄、性别、积分等,这时候在需要修改其中某一项时,通常需要将所有值取出反序列化后,修改某一项的值,再序列化存储回去。这样不仅增大了开销,也不适用于一些可能并发操作的场合(比如两个并发的操作都需要修改积分)。而Redis的Hash结构可以使你像在数据库中Update一个属性一样只修改某一项属性值。
我们简单举个实例来描述下Hash的应用场景,比如我们要存储一个用户信息对象数据,包含以下信息:用户ID为查找的key,存储的value用户对象包含姓名,年龄,生日等信息,如果用普通的key/value结构来存储,主要有以下2种存储方式:
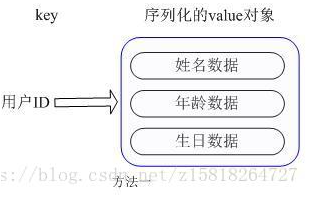
第一种方式将用户 ID 作为查找 key,把其他信息封装成一个对象以序列化的方式存储,这种方式的缺点是,增加了序列化/反序列化的开销,并且在需要修改其中一项信息时,需要把整个对象取回,并且修改操作需要对并发进行保护,引入CAS等复杂问题。
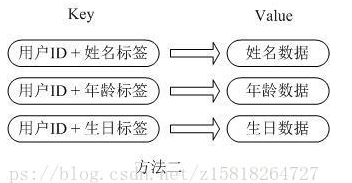
第二种方法是这个用户信息对象有多少成员就存成多少个 key-value 对儿,用用户 ID +对应属性的名称作为唯一标识来取得对应属性的值,虽然省去了序列化开销和并发问题,但是用户 ID 为重复存储,如果存在大量这样的数据,内存浪费还是非常可观的。
那么 Redis 提供的 Hash 很好的解决了这个问题,Redis 的 Hash 实际是内部存储的 Value 为一个 HashMap,并提供了直接存取这个 Map 成员的接口,如下图:
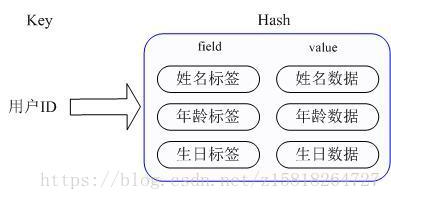
也就是说,Key 仍然是用户 ID,value 是一个 Map,这个 Map 的 key 是成员的属性名,value 是属性值,这样对数据的修改和存取都可以直接通过其内部 Map 的 Key(Redis 里称内部 Map 的 key 为 field),也就是通过 key(用户 ID) + field(属性标签)就可以操作对应属性数据了,既不需要重复存储数据,也不会带来序列化和并发修改控制的问题。很好的解决了问题。
这里同时需要注意,Redis 提供了接口(hgetall)可以直接取到全部的属性数据,但是如果内部 Map 的成员很多,那么涉及到遍历整个内部 Map 的操作,由于 Redis 单线程模型的缘故,这个遍历操作可能会比较耗时,而另其它客户端的请求完全不响应,这点需要格外注意。
hash还可以通过hincrby,hlen做统计。
实现方式
上面已经说到 Redis Hash 对应 Value 内部实际就是一个 HashMap,实际这里会有2种不同实现,这个 Hash 的成员比较少时 Redis 为了节省内存会采用类似一维数组的方式来紧凑存储,而不会采用真正的 HashMap 结构,对应的 value redisObject 的 encoding 为 zipmap,当成员数量增大时会自动转成真正的 HashMap,此时 encoding 为 ht。
代码示例
1 | 127.0.0.1:6379> hset myhash field1 kuangshen |
hash变更的数据 user name age,尤其是用户信息之类的,经常变动的数据!hash更适合于对象的存储,String更加适合字符串存储!
Zset(有序集合)
常用命令
zadd,zrange,zrem,zcard等。
使用场景
Redis sorted set 的使用场景与 set 类似,区别是 set 不是自动有序的,而 sorted set 可以通过用户额外提供一个优先级(score)的参数来为成员排序,并且是插入有序的,即自动排序。当你需要一个有序的并且不重复的集合列表,那么可以选择 sorted set 数据结构,比如你需要存储3个有关联事物时候,常见的用户,消息,消息等级;还可以利用zIncrBy,zRevRange,zAdd,zRevRank,zScore等接口做排行榜。
根据商品销售对商品进行排序显示
- 定义商品销售排行榜(sorted set集合),key为goods:sellsort,分数为商品销售数量。
- 商品编号1001的销量是9,商品编号1002的销量是15 - zadd goods:sellsort 9 1001 15 1002
- 有一个客户又买了2件商品1001,商品编号1001销量加2 - zincrby goods:sellsort 2 1001
- 求商品销量前10名 - ZRANGE goods:sellsort 0 10 withscores
抖音热搜
点击视频
- ZINCRBY hotvcr:20200919 1 八佰
- ZINCRBY hotvcr:20200919 15 八佰 2 花木兰
展示当日排行前10条
- ZREVRANGE hotvcr:20200919 0 9 withscores
实现方式
Redis sorted set 的内部使用 HashMap 和跳跃表(SkipList)来保证数据的存储和有序,HashMap 里放的是成员到 score 的映射,而跳跃表里存放的是所有的成员,排序依据是 HashMap 里存的 score,使用跳跃表的结构可以获得比较高的查找效率,并且在实现上比较简单。
代码示例
1 | zadd |
其余API,查官方文档
案例思路:set 排序 存储班级成绩表,工资排序表!
普通消息:1 重要消息:2 带权重进行判断!
排行榜应用实现,取TOP 10
1 | ################################################## |
Pub/Sub
Pub/Sub 从字面上理解就是发布(Publish)与订阅(Subscribe),在Redis中,你可以设定对某一个key值进行消息发布及消息订阅,当一个key值上进行了消息发布后,所有订阅它的客户端都会收到相应的消息。这一功能最明显的用法就是用作实时消息系统,比如普通的即时聊天,群聊等功能。
Transactions
虽然Redis的Transactions提供的并不是严格的ACID的事务(比如一串用EXEC提交执行的命令,在执行中服务器宕机,那么会有一部分命令执行了,剩下的没执行),但是这个Transactions还是提供了基本的命令打包执行的功能(在服务器不出问题的情况下,可以保证一连串的命令是顺序在一起执行的,中间有会有其它客户端命令插进来执行)。Redis还提供了一个Watch功能,你可以对一个key进行Watch,然后再执行Transactions,在这过程中,如果这个Watched的值进行了修改,那么这个Transactions会发现并拒绝执行。
Redis 有哪些好处
速度快,因为数据存在内存中,类似于HashMap,HashMap的优势就是查找和操作的时间复杂度都是O(1)
支持丰富数据类型,支持string,list,set,sorted set,hash
支持事务,操作都是原子性,所谓的原子性就是对数据的更改要么全部执行,要么全部不执行
丰富的特性:可用于缓存,消息,按key设置过期时间,过期后将会自动删除
1)String
常用命令: set/get/decr/incr/mget等;
应用场景: String是最常用的一种数据类型,普通的key/value存储都可以归为此类;
实现方式: String在redis内部存储默认就是一个字符串,被redisObject所引用,当遇到incr、decr等操作时会转成数值型进行计算,此时redisObject的encoding字段为int。
2)Hash
常用命令: hget/hset/hgetall等
应用场景: 我们要存储一个用户信息对象数据,其中包括用户ID、用户姓名、年龄和生日,通过用户ID我们希望获取该用户的姓名或者年龄或者生日;
实现方式: Redis的Hash实际是内部存储的Value为一个HashMap,并提供了直接存取这个Map成员的接口。Key是用户ID, value是一个Map。这个Map的key是成员的属性名,value是属性值。这样对数据的修改和存取都可以直接通过其内部Map的Key(Redis里称内部Map的key为field), 也就是通过 key(用户ID) + field(属性标签) 就可以操作对应属性数据。
当前HashMap的实现有两种方式:当HashMap的成员比较少时Redis为了节省内存会采用类似一维数组的方式来紧凑存储,而不会采用真正的HashMap结构,这时对应的value的redisObject的encoding为zipmap,当成员数量增大时会自动转成真正的HashMap,此时encoding为ht。
3)List
常用命令: lpush/rpush/lpop/rpop/lrange等;
应用场景: Redis list的应用场景非常多,也是Redis最重要的数据结构之一,比如twitter的关注列表,粉丝列表等都可以用Redis的list结构来实现;
实现方式: Redis list的实现为一个双向链表,即可以支持反向查找和遍历,更方便操作,不过带来了部分额外的内存开销,Redis内部的很多实现,包括发送缓冲队列等也都是用的这个数据结构。
4)Set
常用命令: sadd/spop/smembers/sunion等;
应用场景: Redis set对外提供的功能与list类似是一个列表的功能,特殊之处在于set是可以自动排重的,当你需要存储一个列表数据,又不希望出现重复数据时,set是一个很好的选择,并且set提供了判断某个成员是否在一个set集合内的重要接口,这个也是list所不能提供的;
实现方式: set 的内部实现是一个 value永远为null的HashMap,实际就是通过计算hash的方式来快速排重的,这也是set能提供判断一个成员是否在集合内的原因。
5)Sorted Set
常用命令: zadd/zrange/zrem/zcard等;
应用场景: Redis sorted set的使用场景与set类似,区别是set不是自动有序的,而sorted set可以通过用户额外提供一个优先级(score)的参数来为成员排序,并且是插入有序的,即自动排序。当你需要一个有序的并且不重复的集合列表,那么可以选择sorted set数据结构,比如twitter 的public timeline可以以发表时间作为score来存储,这样获取时就是自动按时间排好序的。
实现方式: Redis sorted set的内部使用HashMap和跳跃表(SkipList)来保证数据的存储和有序,HashMap里放的是成员到score的映射,而跳跃表里存放的是所有的成员,排序依据是HashMap里存的score,使用跳跃表的结构可以获得比较高的查找效率,并且在实现上比较简单。